MozillaOcho是瀏覽器公司的創新和實驗小組,其有趣的創新之一是Llamafile,這是一種從單個文件分發和運行人工智能大型語言模型(LLM)的簡便方法。今天晚上發佈的Llamafile0.8.2是最新版本,更新Llama.cpp,最令人興奮的是對AVX2性能進行優化。
Llamafile 的目標是讓用戶和開發人員更容易獲得人工智能 LLM,它支持從單個文件精簡部署大型語言模型,這些模型既能在 CPU 和 GPU 上執行,也能跨平臺運行。Llamafile 已經支持利用 AVX/AVX2 實現更快的性能,並支持 AVX-512 以實現更快的速度。在今天發佈的 Llamafile 0.8.2 中,又增加 AVX2 優化功能。
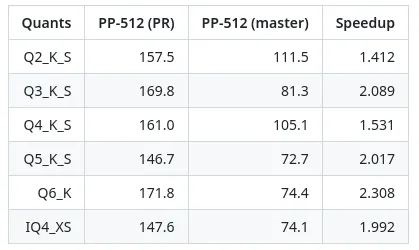
Llamafile 0.8.2 發佈說明中提到
"此版本為 K-quants 和 IQ4_XS 引入更快的 AVX2 提示處理。這是由 @ikawrakow 貢獻給 llamafile 的,他在去年發明K-quants:gerganov/llama.cpp@99009e7。在之前的版本中,我們推薦使用傳統的Q4_0 quant,因為它最簡單、最直觀,可以與最近的 matmul 優化一起使用。多虧 Iwan Kawrakow 的努力,現在(在現代 x86 系統上)最好的quants(如 Q5_K_M)將以最快的速度運行"。
在過去幾年中,英特爾和 AMD 處理器廣泛支持高級矢量擴展 2(Advanced Vector Extensions 2):大多數英特爾 CPU 從 Haswell 開始支持高級矢量擴展 2,而 AMD 方面則從 Excavator CPU 開始支持高級矢量擴展 2。
拉取請求指出,在更快的 AVX2 提示處理方面取得一些令人振奮的成果。據報告,各種計算器具的速度都提高 1.4 至 2.3 倍。
大量參與 Llamafile 開發工作的 Justine Tunney 最初回應拉取請求:
"這是一個不起的變化 @ikawrakow。我很高興看到最好的量化格式現在能以最快的速度運行。在 x86-64 機器上,我一直看到提示處理的速度提高 1.2-2.0 倍。你們甚至成功地使令牌生成速度更快(我發現這要困難得多),在某些情況下甚至提高 1.33 倍!"
對於 Llamafile 0.8.2 而言,這些針對提示處理的 AVX2 優化已經足夠令人興奮。不過,0.8.2 版還帶來內存錯誤修復、文本生成的輕微性能優化、本周的 Llama.cpp 代碼更新以及各種新標志。
有關 Llamafile 0.8.2 版的下載和更多詳情,請訪問GitHub。針對新版本的新Llamafile 基準測試即將發佈。