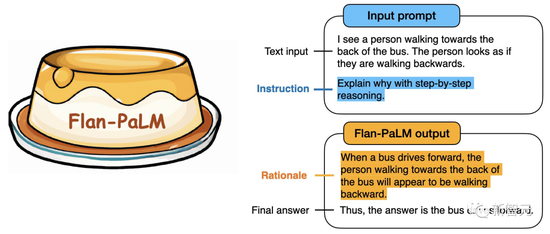
最近,谷歌研究員發佈關於指令微調的最新工作!然而卻宣傳圖中出現可笑的烏龍。幾個小時之前,谷歌大腦的研究員們非常開心地曬出自己最新的研究成果:“我們新開源的語言模型Flan-T5,在對1,800多種語言的任務進行指令微調後,顯著提高prompt和多步推理的能力。”
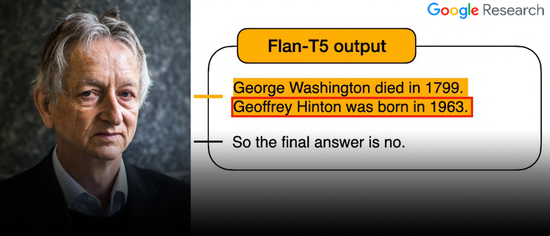
然而,就在這張精心制作的“宣傳圖”上,竟藏著一個讓人哭笑不得的bug!

請註意看Geoffrey Hinton的出生日期:

但實際上,Hinton出生於1947年……

雖然沒有必然聯系,但是Google自己的模型,竟然會把自傢大佬的生日搞錯?
馬庫斯同志看完直接就驚:你們Google,沒人負責審核的嗎……

理論上,這篇擁有31位作者,外加Jeff Dean這種大佬參與的論文,不應該發生這種“低級錯誤”才對啊。

“復制”的時候“打錯”而已!
很快,論文的共同一作就在馬庫斯的推文下面進行回復:“我們都知道,模型的輸出並不總是符合事實。我們正在進行負責任的AI評估,一旦有結果,我們將立即更新論文。”

沒過多久,這位作者刪除上面那條推文,並更新留言稱:“這隻是在把模型的輸出復制到Twitter上時,『打錯』而已。”

對此,有網友調侃道:“不好意思,你能不能給我翻譯翻譯,什麼叫『復制』來著?”

當然,在查看原文之後可以發現,“圖1”所示的生日,確實沒錯。
至於在宣傳圖中是如何從“1947”變成“1963”的,大概隻有做圖的那位朋友自己知道。

隨後,馬庫斯也刪除自己的這條推文。
世界重歸平靜,就像什麼也沒有發生一樣。
隻留下Google研究員自己推文下面的這條在風中飄搖——

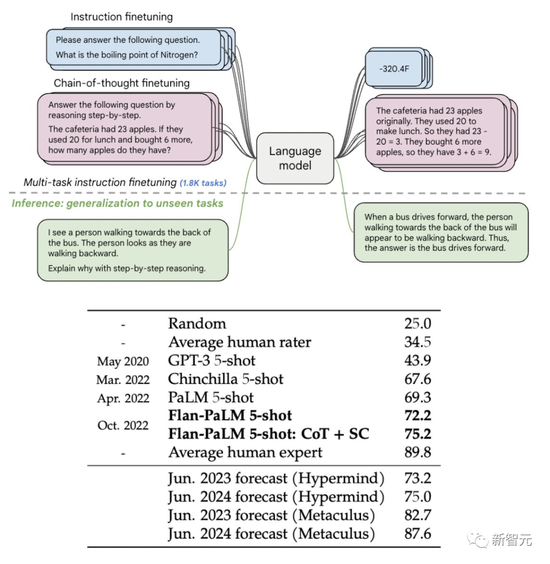
擴展指令微調語言模型
既然誤會解除,我們就讓話題重新回到論文本身上來吧。
去年,Google推出一個參數量隻有1370億的微調語言網絡FLAN(fine-tuned language net)。

https://arxiv.org/abs/2109.01652
FLAN是Base LM的指令調優(instruction-tuned)版本。指令調優管道混合所有數據集,並從每個數據集中隨機抽取樣本。
研究人員稱,這種指令調節(instruction tuning)通過教模型如何執行指令描述的任務來提高模型處理和理解自然語言的能力。
結果顯示,在許多有難度的基準測試中,FLAN的性能都大幅超過GPT-3。
這次,Google將語言模型進行拓展之後,成功刷新不少基準測試的SOTA。
比如,在1.8K任務上進行指令微調的Flan-PaLM 540B,性能明顯優於標準的PALM 540B(平均 + 9.4%),並且在5-shot的MMLU上,Flan-PaLM也實現75.2%的準確率。
此外,作者還在論文中公開發佈Flan-T5檢查點。即便是與更大的模型(如PaLM 62B)相比,Flan-T5也能實現強大的小樣本性能。

論文地址:https://arxiv.org/abs/2210.11416
總結來說,作者通過以下三種方式擴展指令微調:
擴展到540B模型
擴展到1.8K的微調任務
在思維鏈(CoT)數據上進行微調
作者發現具有上述方面的指令微調顯著提高各種模型類(PaLM、T5、U-PaLM)、prompt設置(zero-shot、few-shot、CoT)和評估基準(MMLU、BBH、 TyDiQA、MGSM、開放式生成)。
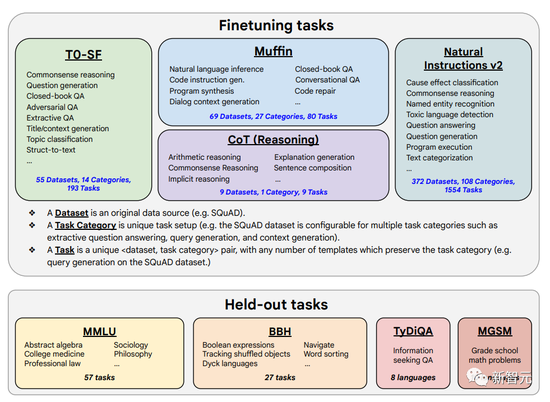
這次的微調數據包括473個數據集、146個任務類別和1,836個總任務。
作者是通過結合之前工作中的四種混合(Muffin、T0-SF、NIV2 和 CoT),縮放(scale)成下圖中的1836個微調任務。
在研究中,微調數據格式如下圖這樣組合。研究者在有樣本/無樣本、有思想鏈/無思想鏈的情況下進行微調。要註意的是,其中隻有九個思維鏈(CoT)數據集使用CoT格式。
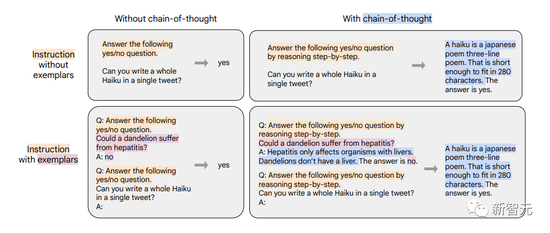
第四種微調數據的混合涉及CoT註釋,作者用它來探索CoT註釋的微調是否可以提高看不見的推理任務的性能。
作者從先前的工作中創建9個數據集的新混合,然後由人類評估者手動為訓練語料庫編寫CoT註釋。這9個數據集包括算數推理、多跳推理(multi-hop reasoning)和自然語言推理等。
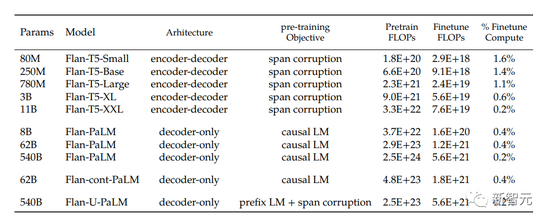
作者在廣泛的模型中應用指令微調,包括T5、PaLM和U-PaLM。對於每個模型,作者都采用相同的訓練過程,使用恒定的學習率,並使用Adafactor優化器進行微調。
從下表中可以看出,用於微調的計算量僅占訓練計算的一小部分。
作者根據模型的大小和微調任務的數量,在保留任務的性能上檢測縮放的影響。
作者從對三種大小的PaLM模型(8B/62B/540B)進行實驗,從任務最少的混合開始,一次添加任務混合,然後再到任務最多的混合(CoT、Muffin、T0-SF 和 NIV2)。
作者發現,擴展指令微調後,模型大小和任務數量的擴展都會大大改善性能。
是的,繼續擴展指令微調就是最關鍵的要點!
不過,在282個任務之後,收益開始略微變小。
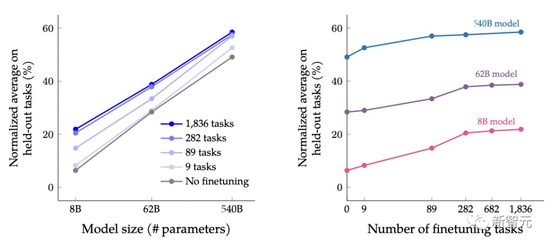
從下表中可以看出,對於三種大小的模型,多任務指令微調後,相比沒有微調時,性能有很大的提高,性能增益范圍從9.4%到15.5%。
其次,增加微調數量可以提高性能,盡管大部分的改進來自282個任務。
最後,將模型規模增加一個數量級(8B→62B或62B→540B)會顯著提高微調和非微調模型的性能。
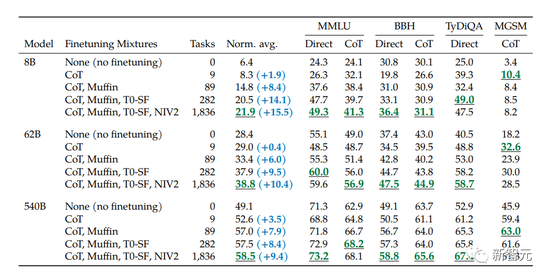
為什麼282個任務之後增益就變小呢?有兩種解釋。
一是附加任務不夠多樣化,因此沒有為模型提供新知識。
二是多任務指令微調的大部分收益,是因為模型學習更好地表達它在預訓練中已經知道的知識,而282個以上的任務並沒有太大的幫助。
另外,作者還探討在指令微調混合中包含思想鏈(CoT)數據的效果。
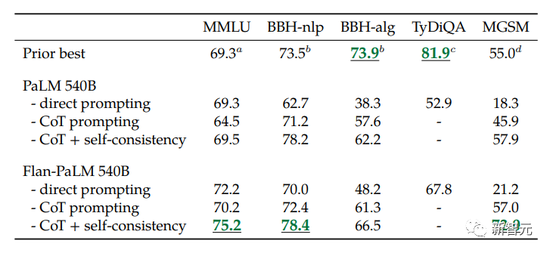
可以看出,Flan-PaLM在所有評估基準上都優於PaLM。
不過令人驚訝的是,以前的指令微調方法(如FLAN,T0)顯著降低non-CoT的性能。
對此的解決方案是,隻需在微調混合中添加9個CoT數據集,就可以在所有評估中獲得更好的性能。
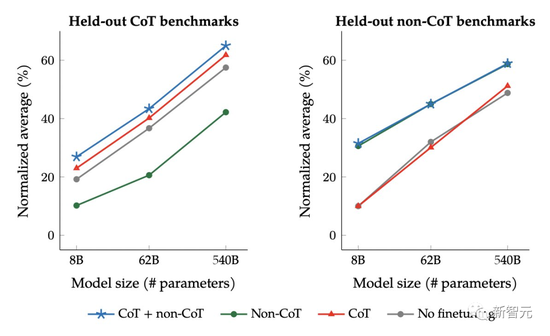
雖然思維鏈(Chain-of-Thought)prompting通常非常有效,但隻能編寫少量樣本,而且零樣本CoT並不總是有效果。
而Google研究者的CoT微調顯著提高零樣本推理能力,比如常識推理。
為展示方法的通用性,研究人員訓練T5、PaLM和U-PaLM。其中參數量的覆蓋范圍也非常廣,從8000萬到5400億。
結果證明,所有這些模型都得到顯著提升。
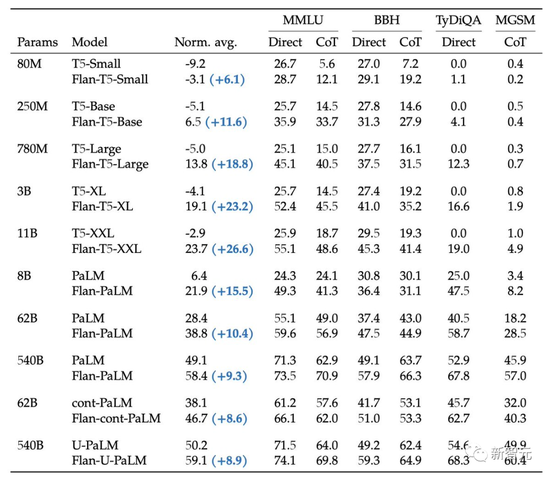
在以往,開箱即用的預訓練語言模型可用性通常都很差,比如對輸入的prompt沒有反應。
Google的研究者要求人類評估者來評估開放式生成問題的“模型可用性”。
結果顯示,Flan-PaLM 的可用性比PaLM基礎模型要高79%。
此外,指令微調還補充其他的模型適應技術,比如UL2R。
同樣的,Flan-U-PaLM取得很多優秀的結果。

論文地址:https://arxiv.org/abs/2210.11399
Google的另一起“翻車”事件
可以說,剛剛發生的這個劇情,既視感相當強!
沒錯,就在10月19日,當GooglePixel的官方賬號試圖挖苦蘋果CEO庫克時,被網友抓包:是用iPhone發的推文……
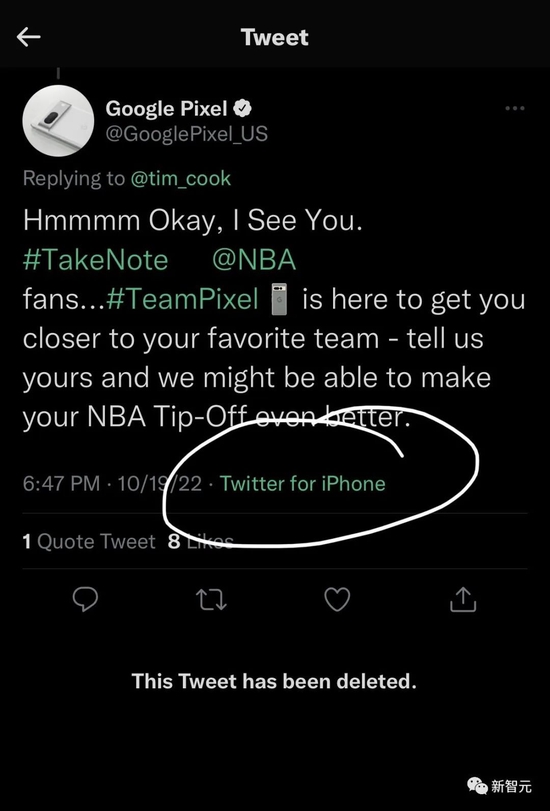
顯然,這種事情早已不是第一次。
2013年,T-Mobile的CEO就在Twitter上對三星Note 3贊不絕口,但用的是iPhone。
同樣是2013年,黑莓的創意總監Alicia Keys在發佈會上說,她已經拋棄自己之前的iPhone,換黑莓Z10。隨後,就被發現用iPhone發推,甚至在被抓到後發推狡辯說是因為自己被黑。
三星,也不例外:
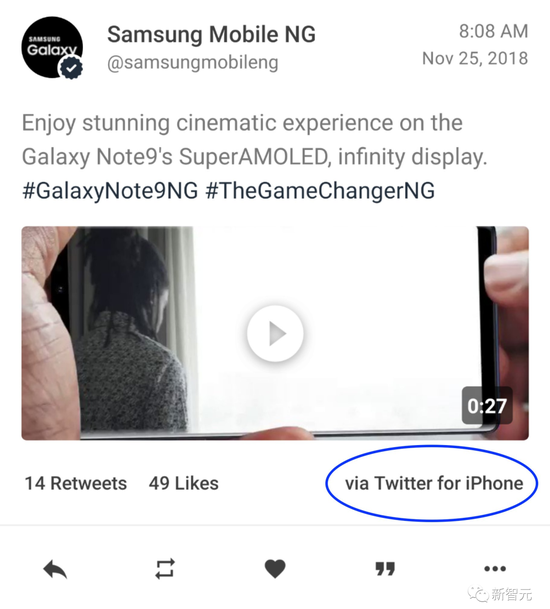
而且,相比於Google的這次刪推,三星當時做得更加決絕:直接刪號!
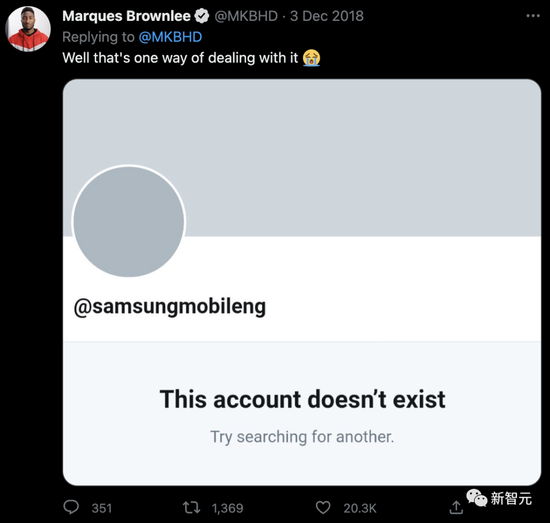
看來,營銷課程有必要加上這樣的一條戒律:如果你要推廣一個產品,請不要用競爭對手的產品來做。
這並不是一個難以傳授的信息,甚至還可以做得直白:在推銷其他產品時,手裡請不要拿著iPhone。