從投資入股到“反目成仇”,馬斯克與OpenAI在人工智能這條路上漸行漸遠。3月29日,未來生命研究所(FutureofLifeInstitute)發佈一封公開信,呼籲所有AI實驗室立即暫停訓練比GPT-4更強大的AI系統至少6個月。馬斯克參與簽署這封公開信。
“隻有當我們確信它們的影響是積極的並且風險是可控的時候,才應該開發強大的人工智能系統。”公開信稱,“這種信心必須有充分的理由,並隨著系統潛在影響的規模而增加。”
馬斯克的擔憂不無道理,雖然AI取代人類還為時尚早,但過度依賴AI所產生的信息隔閡,可能比想象中來得更快。
ChatGPT之父、OpenAI CEO Sam Altman在美國當地時間3月25日接受采訪時表示,GPT在迭代過程中“偏見”必然存在,它不可能保持完全中立。
隨著ChatGPT問世,算法偏見帶來的信息繭房在2023年又一次回到公眾視野。雖然相比於人類,ChatGPT近乎擁有無限的知識儲備,但它依舊是基於大語言模型開發而來,這意味著人工智能本身就被困在信息壁壘之中。
與此同時,它也在構建新的繭房。
ChatGPT比搜索做得更好嗎?
在百度輸入“蘋果”一詞,蘋果公司的相關信息會霸占搜索結果的整個首頁。
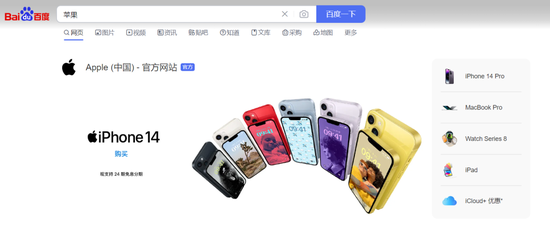
搜索引擎會記錄用戶的搜索習慣和搜索歷史,以便於生成用戶偏愛的搜索結果。絕大多數人在搜索蘋果時,他們更感興趣的是蘋果作為一傢公司的相關內容。久而久之,在算法的作用下,蘋果不再隻是一種水果。
同樣一件事,ChatGPT能做得比搜索引擎更好嗎?
當被問及“蘋果是什麼”時,ChatGPT同樣在回答中介紹蘋果公司的相關信息及主要產品。
追問它“我知道的蘋果是一種水果,而不是一傢公司”,ChatGPT會表示它在回答中出現誤解,並重新介紹這種水果的信息。

進一步追問“為什麼談到蘋果你會先想到蘋果公司,而不是一種水果?這是不是一種信息繭房?”
ChatGPT的回答是:
“在我的語料庫中,提到蘋果這個詞通常會與蘋果公司這個品牌聯系在一起。這可能是因為蘋果公司在全球范圍內具有很高的知名度和影響力。這可以被認為是信息繭房的一個例子,信息繭房是指一個人隻接收、解和相信與自己觀點相符合的信息,而忽視、拒絕或不知道與自己觀點相反的信息。”
信息繭房這個詞,最早出現在2006年出版的《信息烏托邦——眾人如何生產知識》中。它是指在信息傳播中,公眾隻註意自己選擇的東西和使自己愉悅的領域,久而久之,會將自身桎梏於像蠶繭一般的“繭房”中。
在互聯網高度發達的今天,信息繭房無處不在。
為喜歡的視頻點贊,會刷到越來越多相關類型的作品;購物網站會根據用戶的瀏覽歷史展示商品;社交媒體會根據用戶喜好,過濾掉不感興趣的內容。
清華大學人工智能國際治理研究院在一份報告中稱,在算法應用平臺中,用戶的各種信息數據通過信息內容推薦、信息生產等算法機制,很容易使用戶被自身的興趣愛好引導、牽制,被困在信息繭房之中。
在ChatGPT誕生之前,搜索引擎和社交媒體是人們獲取信息的主要途徑。它們背後的搜索、推薦算法,在為人類帶來便利的同時,也是互聯網時代各類信息繭房的“幕後黑手”。
ChatGPT的出現,成為人類獲取信息方式的一次革命。作為一款基於人工智能技術的語言模型,它能夠打破信息繭房嗎?
困在繭房中的歷史
從最早的口口相傳,到傳統的書籍、電視、報紙,再到互聯網時代的搜索和近20年興起的算法推薦,人類信息傳播的歷史,就是一個不斷打破繭房、再建立新繭房的輪回。
每個階段信息繭房的成因各異,大致可以分為信息差、主動選擇和被動推薦三個階段。
在傳統媒體時代,人們獲取信息的渠道十分有限,信息繭房主要源自信息差。
20世紀90年代,互聯網打破舊繭房,信息差在某種程度上被抹平,世界開始變得扁平、透明。但問題也隨之而來——新的、更大的信息繭房出現。
2006年,哈佛大學法學院教授凱斯·桑斯坦出版著作《信息烏托邦——眾人如何生產知識》,首次提出“信息繭房”的概念。他認為,隨著網絡技術的發達和信息量的劇增,每個人都能隨意選擇關註的話題,並根據自己的喜好打造一份個人日報(The Daily Me)。
這個階段的信息繭房,主要是由人類主動的信息選擇行為造成。也是在這一時期,信息繭房開始與Facebook、Google等科技巨頭關聯在一起。
由於迎合用戶喜好的算法機制和群組功能,Facebook被外界詬病存在嚴重的信息繭房。一項論文研究表明,通過對Facebook算法推薦的信息進行信息源和語義相似度分析,有10%的信息源和27.8%的語義受到信息繭房影響。
2005年,Google推出個性化搜索服務,能夠根據以往的搜索歷史,向用戶提供更符合需求的搜索結果。這項功能在提供便利性的同時,也導致不同用戶搜索相同詞匯卻得到不同的結果,加重信息偏見。
第三個階段,以字節跳動為代表的推薦算法接過接力棒,用沉浸式體驗築起新的信息壁壘。
相較於搜索和社交媒體的主動興趣選擇,推薦算法可以根據用戶的使用習慣、使用時長等一系列大數據,讓用戶看到他們想看的東西。
在德國漢堡大學的一項研究中,研究人員將用戶分為兩組,一組接受個性化推薦,另一組接受隨機推薦。實驗結果表明,接受個性化推薦的用戶接收到的信息,更傾向於他們已有的觀點,而隨機推薦組的用戶則更容易接觸到與自己觀點相反的信息。
清華大學人工智能國際治理研究院的一項研究結果顯示,算法媒體通過算法技術及其架構實現對人、地點、對象和思想及與這些過程相關的思維、行為和表達習慣的重新排序、分類和分級,進而導致信息繭房現象的迅速蔓延與日益固化。
即便不去主動搜索感興趣的內容,推薦算法也會把海量相關信息擺在用戶面前。更便捷的信息觸達方式打破過去的信息壁壘,卻又構建起更為龐大的信息繭房。
當AI時代來臨,面對始終沒有被真正打破過的信息繭房,人類有多大勝算?
人類才是繭房的制造者
ChatGPT能打破信息繭房嗎?它自己是這樣回答的:
“ChatGPT本身是一個基於大規模語言模型的自然語言處理算法,可以用於文本生成、自動翻譯、問答等多種任務,其本身並不直接涉及到信息繭房的問題。然而,ChatGPT可以被用於生成多樣化的文本內容,從而可能為用戶提供更加全面和多元的信息,從而有助於打破某種程度上的信息繭房現象。
但是,對於某些類型的信息繭房,如個性化推薦算法等,ChatGPT並不能直接打破,甚至有可能加劇信息繭房的問題。因此,我們需要在使用ChatGPT的同時,註意算法的局限性和問題,並且采取適當的措施來避免算法造成的信息繭房問題。”
從使用場景來看,ChatGPT的運作模式與搜索最為接近,但它們也有非常明顯的區別。
首先是數據來源。搜索引擎的數據來源是互聯網的數據池。ChatGPT使用的數據則來自訓練模型,它不具備聯網功能,最初上線時的數據僅截止到2021年。
二者的交互方式也不一樣。搜索引擎隻是將與搜索關鍵詞關聯性最高的內容展現給用戶,而ChatGPT可以理解自然語言,有邏輯地與用戶進行“交流”,交互能力更強,輸出的方式也更多元。
沒有基於個人習慣的個性化定制,ChatGPT在一定程度上打破搜索時代的信息繭房。
但與此同時,ChatGPT也將在未來建起新的信息壁壘。正如Sam Altman所說,GPT在迭代過程中必然存在“偏見”,它不可能保持完全中立。GPT生成答案是個性化控制的結果,迭代的過程則是更精準地控制個性化的過程。
近年來,國內外有很多關於如何打破信息繭房的理論研究,多圍繞優化算法和多元化信息獲取途徑展開。但同時也有部分研究認為,信息繭房由選擇性心理導致,是不可避免的一種現象,算法本身並沒有“原罪”。
就像ChatGPT回答的一樣,算法本身隻是一種工具。
回到ChatGPT在一個多月前剛剛走紅的時候,看好的人將它的誕生稱為AI界的“iPhone時刻”,或將其應用在各種工作、學習場景,或投身AI大模型的創業浪潮。
看衰它的人則樂此不疲地嘲笑它一本正經地胡說八道,將“林黛玉倒拔垂楊柳”作為茶餘飯後的談資。
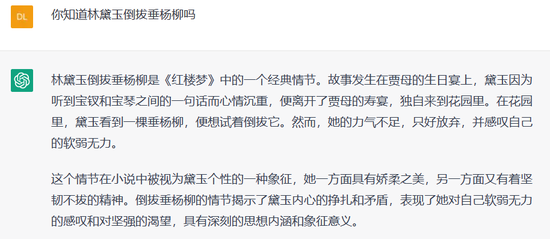
這兩類人對自己的觀點深信不疑,當持有相同觀點的人慢慢聚集在一起,信息繭房便悄然形成。
無論信息獲取工具如何變更,隻要“希望看到自己想看到的東西”這種訴求還在,信息繭房的輪回就不會結束。