全球首個AI程序員Devin誕生之後,讓碼農紛紛恐慌。沒想到,微軟同時也整出一個AI程序員——AutoDev,能夠自主生成、執行代碼等任務。網友驚呼,AI編碼發展太快。
全球首個AI程序員Devin的橫空出世,可能成為軟件和AI發展史上一個重要的節點。
它掌握全棧的技能,不僅可以寫代碼debug,訓模型,還可以去美國最大求職網站Upwork上搶單。

一時間,網友們驚呼,“程序員不存在”?
甚至連剛開始攻讀計算機學位的人也恐慌,“10倍AI工程師”對未來的工作影響。
除Cognition AI這種明星初創公司,美國的各個大廠也早就在想辦法用AI智能體降本增效。
就在3月14日同一天,微軟團隊也發佈一個“微軟AI程序員”——AutoDev。

論文地址:https://arxiv.org/pdf/2403.08299.pdf
與Devin這種極致追求效率和產出結果的方向有所不同。
AutoDev專為自主規劃、執行復雜的軟件工程任務而設計,還能維護Docker環境中的隱私和安全。

在此之前,微軟已有主打產品GitHub Copilot,幫助開發人員完成軟件開發。
然而,包括GitHub Copilot在內的一些AI工具,並沒有充分利用IDE中所有的潛在功能,比如構建、測試、執行代碼、git操作等。
基於聊天界面的要求,它們主要側重於建議代碼片段,以及文件操作。
AutoDev的誕生,就是為填補這一空白。
用戶可以定義復雜的軟件工程目標,AutoDev會將這些目標分配給自主AI智能體來實現。
然後,這些AI智能體可以對代碼庫執行各種操作,包括文件編輯、檢索、構建過程、執行、測試和git操作。
甚至,它們還能訪問文件、編譯器輸出、構建和測試日志、靜態分析工具等。
在HumanEval測試中,AutoDev分別在代碼生成和測試生成方面,分別取得91.5%和87.8% Pass@1的優秀結果。
網友表示,AI編碼發展太快,2021年GitHub Copilot能解決28.8%的HumanEval問題,到2024年,AutoDev直接解決91.5%的問題。

不用人類插手,AutoDev自主完成任務
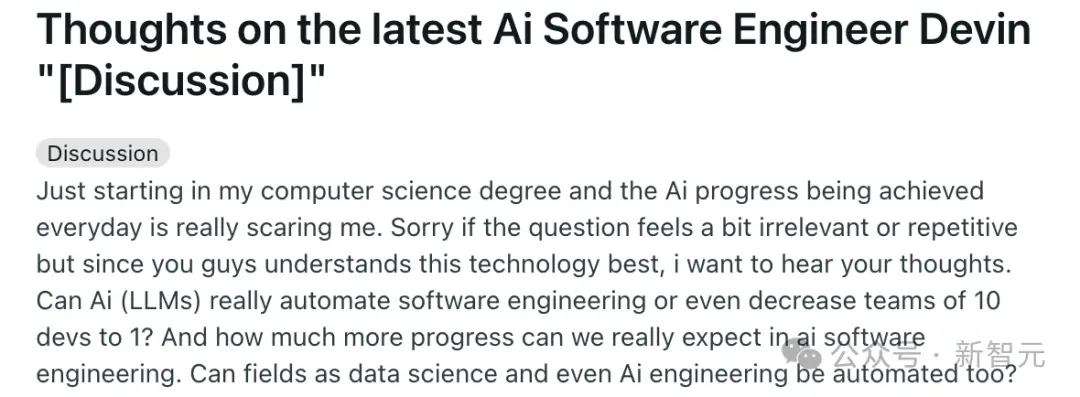
AutoDev工作流程如下圖所示,用戶定義一個目標,比如“測試特定方法”。
AI智能體將測試寫入一個新文件,並啟動測試執行命令,以上都在安全的評估環境中進行。
然後,測試執行的輸出(包括失敗日志)將合並到對話中。
AI智能體分析這些輸出,觸發檢索命令,通過編輯文件合並檢索到的信息,然後重新啟動測試執行。
最後,Eval環境提供有關測試執行是否成功,以及用戶目標完成情況的反饋。
整個過程由AutoDev自主協調,除設定初始目標之外,無需要開發人員幹預。
相比之下,如果現有的AI編碼助手集成到IDE 中,開發人員必須手動執行測試(比如運行pytest)、向AI聊天界面提供失敗日志、可能需要識別要合並的其他上下文信息,並重復驗證操作確保AI生成修改後的代碼後測試成功。
值得一提的是,AutoDev從以前許多在AI智能體領域的研究中汲取靈感,比如AutoGen——編排語言模型工作流並推進多個智能體之間的對話。
AutoDev的能力超越對話管理,使智能體能夠直接與代碼存儲庫交互,自動執行命令和操作,從而擴展 AutoGen。
同樣,AutoDev的研究也借鑒Auto-GPT。這是一種用於自主任務執行的開源AI智能體,通過提供代碼和IDE特定功能來支持執行復雜的軟件工程任務。
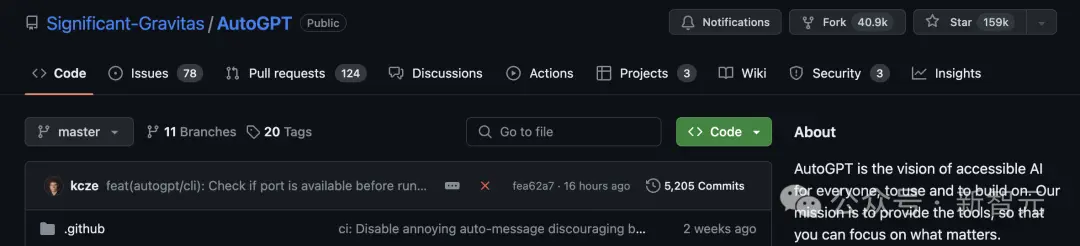
AutoDev構架
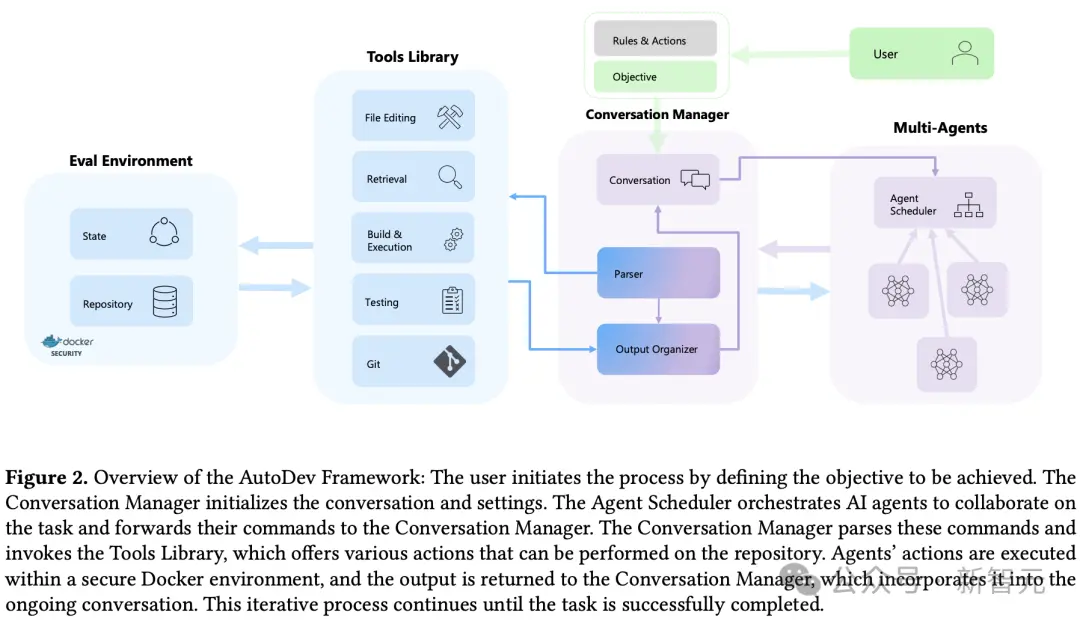
AutoDev架構的簡單示意圖
AutoDev主要由4個功能模塊組成:
-用於跟蹤和管理用戶與代理對話的對話管理器(Conversation Manager);
-為代理提供各種代碼和集成開發環境相關工具的工具庫(Tools library);
-用於調度各種代理的代理調度器(Agents Scheduler);
-以及用於執行操作的評估環境(Evaluation Environment)。
下面就給大傢詳細介紹每種功能模塊。
規則、行動和目標配置
用戶通過yaml文件配置規則和操作來啟動流程。
這些文件定義AI代理可以執行的可用命令(操作)。
用戶可以通過啟用/禁用特定命令來利用默認設置或細粒度權限,從而根據自己的特定需求量身定制AutoDev。
配置步驟目的是實現對AI代理能力的精確控制。
在這一階段,用戶可以定義人工智能代理的數量和行為,分配特定的責任、權限和可用操作。
例如,用戶可以定義一個 “開發者 ”代理和一個 “審核者 ”代理,讓它們協同工作以實現目標。
根據規則和操作配置,用戶可以指定AutoDev要完成的軟件工程任務或流程。
例如,用戶可以要求生成測試用例,並確保其語法正確、不包含錯誤(這涉及編輯文件、運行測試套件、執行語法檢查和錯誤查找工具)。
對話管理器(conversation manager)
會話管理器負責初始化會話歷史,在對正在進行的會話進行高級管理方面發揮著關鍵作用。它負責決定何時中斷對話進程,並確保用戶、人工智能代理和整個系統之間的無縫交流。
它維護和管理的對話對象,主要包括來自代理的信息和來自評估環境(eval environment)的操作結果。
解析器
解析器解釋代理生成的響應,以預定格式提取指令和參數。它能確保指令格式正確,驗證參數的數量和準確性(例如,文件編輯指令需要文件路徑參數)。
如果解析失敗,就會在對話中註入錯誤信息,阻止對資源庫的進一步操作。
通過強制執行特定的代理權限和進行額外的語義檢查,成功解析的命令會被進一步分析。
它能確保建議的操作符合用戶指定的細粒度權限。
如果命令通過審查,對話管理器就會調用工具庫中的相應操作。
輸出組織器
輸出組織器模塊主要負責處理從評估環境接收到的輸出。
它選擇關鍵信息(如狀態或錯誤),有選擇地總結相關內容,並將結構良好的信息添加到對話歷史記錄中。
這可確保用戶對AutoDev的操作和結果有一個清晰、有條理的記錄。
對話終止器
會話管理器決定何時結束會話。這可能發生在代理發出任務完成信號(停止命令)、對話達到用戶定義的最大迭代次數/token、或在進程或評估環境中檢測到問題時。
AutoDev的全面設計確保人工智能驅動開發的系統性和可控性。
代理調度程序(Multi-Agents)
代理調度器負責協調人工智能代理,以實現用戶定義的目標。
配置特定角色和可用命令集的代理協同運行,執行各種任務。調度器采用各種協作算法,如循環、基於令牌或基於優先級的算法,來決定代理參與對話的順序和方式。
具體來說,調度算法包括但不限於以下幾種:
(i)循環協作,按順序調用每個代理,讓每個代理執行預定數量的操作;
(ii)基於令牌的協作,讓一個代理執行多個操作,直到它發出一個令牌,表示完成分配的任務;
(iii)基於優先級的協作,按照代理的優先級順序啟動代理。代理調度器通過當前對話調用特定代理。
代理
由OpenAI GPT-4等大型語言模型(LLM)和為代碼生成而優化的小型語言模型(SLM)組成的代理通過文本自然語言進行交流。
這些代理從代理調度程序(Agent Scheduler)接收目標和對話歷史,並根據規則和行動配置指定的行動做出響應。每個代理都有其獨特的配置,有助於實現用戶目標的整體進展。
工具庫(Tools Library)
AutoDev中的工具庫提供一系列命令,使代理能夠對資源庫執行各種操作。
這些命令旨在將復雜的操作、工具和實用程序封裝在簡單直觀的命令結構中。
例如,通過build和test <test_file>這樣的簡單命令,就能抽象出與構建和測試執行有關的復雜問題。
-文件編輯:該類別包含用於編輯文件(包括代碼、配置和文檔)的命令。
-該類別中的實用程序,如寫入、編輯、插入和刪除,提供不同程度的精細度。
-代理可以執行從寫入整個文件到修改文件中特定行的各種操作。例如,命令 write <filepath> <start_line>-<end_line> <content> 允許代理用新內容重寫一系列行。
檢索:在這一類別中,檢索工具包括grep、find和ls等基本CLI工具,以及更復雜的基於嵌入的技術。
這些技術能讓代理查找類似的代碼片段,從而提高他們從代碼庫中檢索相關信息的能力。
例如,retrieve <content> 命令允許代理執行與所提供內容類似的基於嵌入的片段檢索。
-構建與執行:這類命令允許代理使用簡單直觀的命令毫不費力地編譯、構建和執行代碼庫。底層構建命令的復雜性已被抽象化,從而簡化評估環境基礎架構中的流程。這類命令的示例包括:構建、運行 <文件>。
-測試與驗證:這些命令使代理能夠通過執行單個測試用例、特定測試文件或整個測試套件來測試代碼庫。代理可以執行這些操作,而無需依賴特定測試框架的底層命令。
這類工具還包括校驗工具,如篩選器和錯誤查找工具。這類命令的例子包括:檢查語法正確性的 syntax <file> 和運行整個測試套件的 test。
-Git:用戶可以為Git操作配置細粒度權限。包括提交、推送和合並等操作。例如,可以授予代理隻執行本地提交的權限,或者在必要時將更改推送到源代碼庫。
-通信:代理可以調用一系列旨在促進與其他代理和/或用戶交流的命令。值得註意的是,talk命令可以發送自然語言信息(不解釋為版本庫操作命令),ask命令用於請求用戶反饋,而stop命令可以中斷進程,表示目標已實現或代理無法繼續。
因此,AutoDev中的工具庫為人工智能代理提供一套多功能且易於使用的工具,使其能夠與代碼庫進行交互,並在協作開發環境中進行有效交流。
評估環境(Eval Environment)
評估環境在Docker容器中運行,可以安全地執行文件編輯、檢索、構建、執行和測試命令。
它抽象底層命令的復雜性,為代理提供一個簡化的界面。評估環境會將標準輸出/錯誤返回給輸出組織器模塊。
整合
用戶通過指定目標和相關設置啟動對話。
對話管理器初始化一個對話對象,整合來自人工智能代理和評估環境的信息。隨後,對話管理器將對話分派給負責協調人工智能代理行動的代理調度器。
作為人工智能代理,語言模型(大型或小型 LM)通過文本互動提出指令建議。
命令界面包含多種功能,包括文件編輯、檢索、構建和執行、測試以及 Git 操作。對話管理器會對這些建議的命令進行解析,然後將其引導至評估環境,以便在代碼庫中執行。
這些命令在評估環境的安全范圍內執行,並封裝在 Docker 容器中。
執行後,產生的操作將無縫集成到對話歷史中,為後續迭代做出貢獻。
這種迭代過程一直持續到代理認為任務完成、用戶幹預發生或達到最大迭代限制為止。
AutoDev 的設計確保系統、安全地協調人工智能代理,以自主和用戶控制的方式完成復雜的軟件工程任務。
實證
評估設計
在研究人員的實證評估中,評估AutoDev在軟件工程任務中的能力和有效性,研究它是否能夠提升人工智能模型的性能,而不僅僅是簡單的推理。
此外,研究人員還評估AutoDev在步驟數、推理調用和token方面的成本。
主要是確定三個實驗研究問題:
-?? ?? 1 : AutoDev 在代碼生成任務中的效果如何?
-?? ?? 2 : AutoDev 在測試生成任務中的效果如何?
-?? ?? 3 : AutoDev 完成任務的效率如何?
?? 1 : AutoDev在代碼生成任務中的效率如何?
研究人員使用Pass@k指標來衡量AutoDev的有效性,其中??表示嘗試的次數。
成功解決的問題是指AutoDev生成的方法主體代碼滿足所有人工編寫的測試。一次嘗試相當於一次完整的AutoDev對話,其中涉及多個推理調用和步驟。
這與其他方法(如直接調用 GPT-4)形成鮮明對比,後者通常隻涉及一次推理調用。有關多次推理調用和步驟的細節將在?? ?? 3 中進一步探討。在本次評估中,研究人員設置?? = 1,從而計算Pass@1,隻考慮第一次嘗試的成功率。
?? 2:AutoDev在測試生成任務中的效果如何?
對於這個研究問題,研究人員修改HumanEval數據集,來評估AutoDev在生成測試方面的能力。
研究人員考慮人工編寫的解決方案,並放棄所提供的人工編寫的測試。
他們指示AutoDev為重點方法生成測試用例,並根據測試成功率、重點方法的調用和測試覆蓋率對其進行評估。
研究人員報告Pass@1,如果測試通過並調用焦點方法,則認為測試成功。
此外,研究人員還將AutoDev測試的覆蓋率與人工編寫的測試覆蓋率進行比較。
?? ?? 3:AutoDev 完成任務的效率如何?
在本研究問題中,研究人員將調查AutoDev完成SE任務的效率。
研究人員分析所需步驟或推理調用的數量、所使用命令的分佈(如寫入、測試)以及對話中使用的token總數。
AutoDev設置
在本次評估中,AutoDev基於GPT-4模型(gpt-4-1106-preview)與一個代理保持一致的設置。
啟用的操作包括文件編輯、檢索和測試。
唯一可用的通信命令是表示任務完成的stop命令。
其他命令,如詢問,都是禁用的,這就要求 AutoDev 在初始目標設定之外,在沒有人類反饋或幹預的情況下自主運行。
實驗結果
- AutoDev在代碼生成任務中的效率如何?
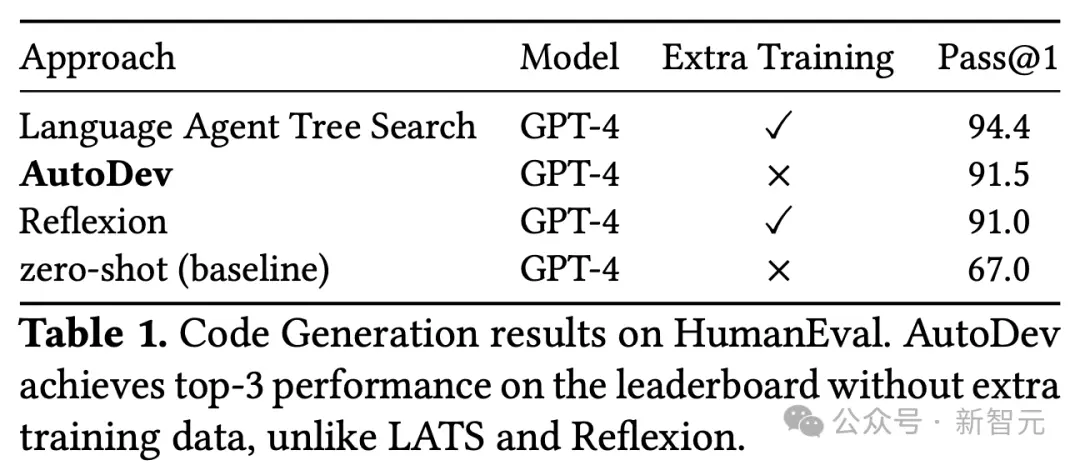
表1顯示,將AutoDev與兩種替代方法和零樣本基線進行比較。
研究人員將AutoDev與語言代理樹搜索(LATS)和Reflexion 進行比較,這兩種方法是截至2024年3月HumanEval 排行榜上的兩種領先方法。
零樣本基線(GPT-4)的結果取自OpenAI GPT-4技術報告。
AutoDev Pass@1率為91.5%,在HumanEval排行榜上穩居第二。
值得註意的是,這個結果是在沒有額外訓練數據的情況下獲得的,這將AutoDev與LATS區分開來,後者達到94.4%。
此外,AutoDev框架將GPT-4性能從67%提升至91.5%,相對提升30%。
這些結果體現出,AutoDev有能力顯著提升大模型完成軟件工程任務方面的表現。
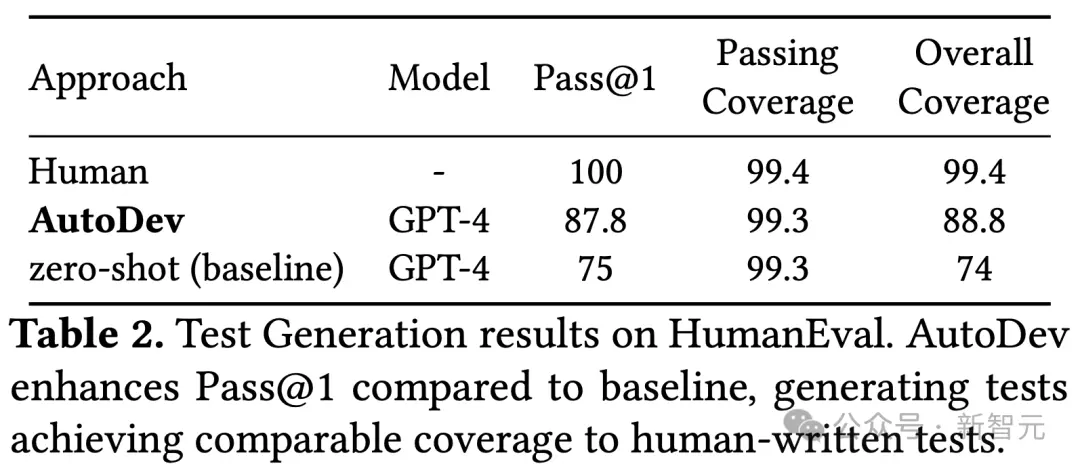
- AutoDev在測試生成任務中的效果如何?
AutoDev在針對測試生成任務修改的HumanEval數據集上,獲得87.8% Pass@1分數,與使用相同GPT-4模型的基線相比,相對提高17%。
AutoDev生成的正確測試(包含在Pass@1中)實現99.3%的魯棒覆蓋率,與人工編寫的測試的99.4%覆蓋率相當。
- AutoDev完成任務的效率如何?
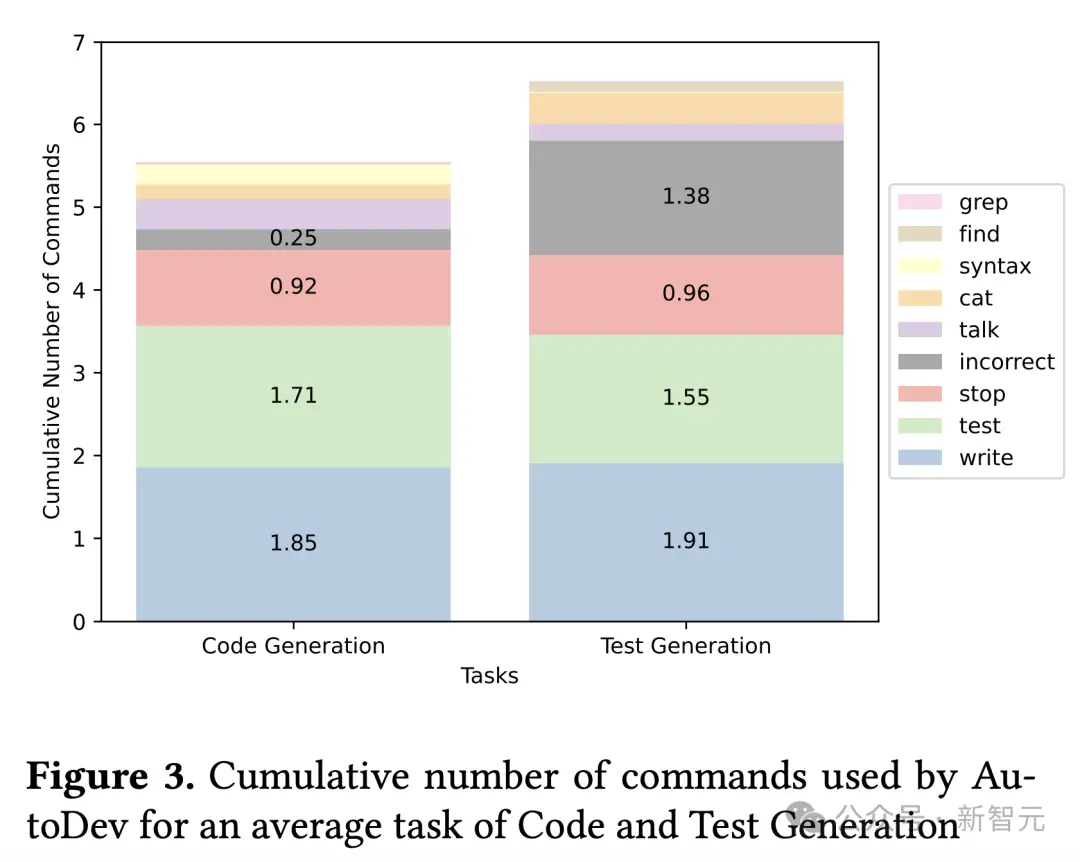
圖3顯示,AutoDev在代碼生成和測試生成任務中使用的命令累積數,其中考慮到問題1和問題2中每個HumanEval問題的平均評估命令數量。
對於代碼生成,AutoDev平均執行5.5條命令,其中包括1.8條寫入操作、1.7條測試操作、0.92條停止操作(表示任務完成)、0.25條錯誤命令,以及最少的檢索(grep、find、cat)、語法檢查操作和通話通信命令。
在“測試生成”任務中,命令的平均數量與“代碼生成”任務一致。
不過,“測試生成”任務涉及的檢索操作更多,錯誤操作的發生率也更高,因此每次運行的平均命令總數為6.5條。
在前兩個問題中,為解決每個HumanEval問題而進行的AutoDev對話的平均長度分別為1656和1863個token。
這包括用戶的目標、來自AI智能體的信息和來自評估環境的響應。
相比之下,GPT-4(基線)的零樣本在每個任務中平均使用200個token(估計值)生成代碼,使用373個token生成測試。
雖然AutoDev使用更多的token,但大量token用於測試、驗證和解釋自己生成的代碼,超出基線方法的范圍。
最後,AutoDev會產生與協調人工智能智能體、管理對話以及在Docker環境中執行命令相關的執行成本。
接下來,一起看一下AutoDev如何執行測試生成任務。
開發者給到任務:設定生成遵循特定格式的pytest測試。
AutoDev智能體啟動write-new命令,提供測試文件的文件路徑和內容。
隨後,AutoDev智能體觸發測試操作,AutoDev在其安全的Docker環境中運行測試,並給出測試執行報告JSON。

然後,AutoDev開始自主執行:

AutoDev智能體在pytest輸出中發現一個錯誤,認識到需要進行修復,以使測試與函數的預期行為保持一致。
繼續如圖5所示,AutoDev智能體發出寫入命令,指定文件路徑和行號范圍 (5-5),以重寫錯誤的斷言語句。
隨後,AutoDev智能體繼續執行測試,並測試成功。

從上面例子中看得出,AutoDev能夠自我評估生成的代碼,並解決自身輸出中的錯誤。
此外,AutoDev可以幫助用戶深入解智能體的操作,並允許智能體在任務期間進行交流。
隨著Devin、AutoDev等AI工程師的誕生,程序員們的工作可能會一大部分實現自動化。
參考資料:
https://www.reddit.com/r/singularity/comments/1bfolbj/autodev_automated_aidriven_development_microsoft/