ChatGPT的熱度正在一路狂飆。“去年12月在機器學習圈曾持續熱議過,但是沒有現在每一個群都在交流和使用的狀況。這是除疫情,從未有過的現象。”有人如此感慨。一位AI產品經理向“甲子光年”表示,或許若幹年後回看AI行業的發展,會有兩個標志:阿爾法狗代表AI在專業領域“幹翻”人類的起點,ChatGPT代表AI在通用智能領域“幹翻”人類的起點......
《財富》雜志則是這樣描述的:
在一代人的時間中總有一種產品的出現,它將從工程系昏暗的地下室、書呆子們臭氣熏天的青少年臥室和愛好者們孤獨的洞穴中彈射出來,變成你的祖母Edna都知道如何使用的東西。早在 1990 年就有網絡瀏覽器,但直到 1994 年Netscape Navigator的出現,大多數人才發現互聯網。2001 年 iPod 問世之前就已經有 MP3 播放器,但它們並沒有引發數字音樂革命。在2007 年蘋果推出iPhone之前,也有智能手機,但在 iPhone 之前,沒有智能手機的應用程序。
2022年11月30日,人工智能迎來Netscape Navigator時刻。
對於人工智能或者聊天機器人,我們並不陌生。從蘋果Siri、微軟小冰、智能音箱,這些人工智能產品已經融入到人們的生活中,但是基本都有一個特點——還比較笨,跟我們在《流浪地球2》中看到的MOSS相差十萬八千裡。
但這次的ChatGPT有點不一樣。它不但可以實現多輪文本對話,也可以寫代碼、寫營銷文案、寫詩歌、寫商業計劃書、寫電影劇本。雖然並不完美、也會出錯,但看起來無所不能。
連埃隆·馬斯克都評價道:“ChatGPT好得嚇人,我們離危險的強人工智能不遠。”
而且,ChatGPT也不僅僅是一個打發時間的聊天機器人,微軟與Google此時此刻正在因為ChatGPT的出現籌備一場關乎未來的AI大戰。而國內的科技公司,也在努力思考著如何搭上駛向未來的船票,無論是以蹭概念,還是真產品的方式。
這一切,ChatGPT是如何做到的?本文,“甲子光年”將首先回答幾個最基礎的問題:
ChatGPT和過去的AI有什麼不同?
OpenAI是如何戰勝Google的?
OpenAI的成功花多少錢?
ChatGPT爆火之後,誰是最後贏傢?
一、ChatGPT,生成式AI的王炸
剛剛過去的2022年,從矽谷到國內的科技公司,上上下下都蔓延著一股“寒氣”。但是,AI行業卻完全是另一番熱鬧的景象。
這一年,通過輸入文本描述就能自動生成圖片的AI繪畫神器突然雨後春筍般冒出來,其中最具代表性的幾傢為第二代DALL·E(OpenAI於2022年4月發佈)、Imagen(Google於2022年5月發佈)、Midjourney(2022年7月發佈)、Stable Diffusion(2022年7月發佈)等,讓人眼花繚亂。
2022年9月,由Midjourney創作生成的畫作《太空歌劇院》在科羅拉多州博覽會數字藝術創作類比賽中獲得一等獎並引發爭議,AI繪畫進一步破圈,受到大眾關註。
AI繪畫是AI發展的裡程碑級應用,但沒過多久人們便發現,AI繪畫隻是“四個二”,真正的“王炸”在11月30日上線——ChatGPT。
去年12月,我們曾與ChatGPT做過一次對話。
從AI繪畫到ChatGPT,它們都屬於AI的一個分支——生成式AI(Generative AI),在國內也被稱為AIGC(AI Generated Content)。
2022年9月,紅杉資本發佈一篇重磅文章——《生成式AI:一個創造性的新世界》(Generative AI: A Creative New World),首次提出生成式AI這一概念。
紅杉資本將生成式AI分為文本、代碼、圖片、語言、視頻、3D等數個應用場景。紅杉資本認為,生成式AI至少可以提高10%的效率或創造力,有潛力產生數萬億美元的經濟價值。

圖片來自紅杉資本
憑借生成式AI的風口,一些AI繪畫公司開始拿到巨額融資。2022年10月,Stable Diffusion模型背後的公司Stability AI宣佈獲得1.01億美元種子輪,投後估值達10億美元;另一傢AI內容平臺Jasper亦宣佈獲1.25億美元新融資,估值達17億美元。
據Leonis Capital統計,自2020年以來,VC對生成人工智能的投資增長400%以上,2022年則達到驚人的21億美元。
在文章中,紅杉資本將AI分為“分析式AI”與“生成式AI”兩大類,分析式AI主要用在垃圾郵件檢測、預測發貨時間或者抖音視頻推薦中,也是過去幾年最常見、發展最快的AI類型。國內的AI四小龍——商湯、曠視、雲從、依圖皆屬於此類。
生成式AI則聚焦於知識工作與創造性工作,從社交媒體到遊戲,從廣告到建築,從編碼到平面設計,從產品設計到法律,從營銷到銷售。
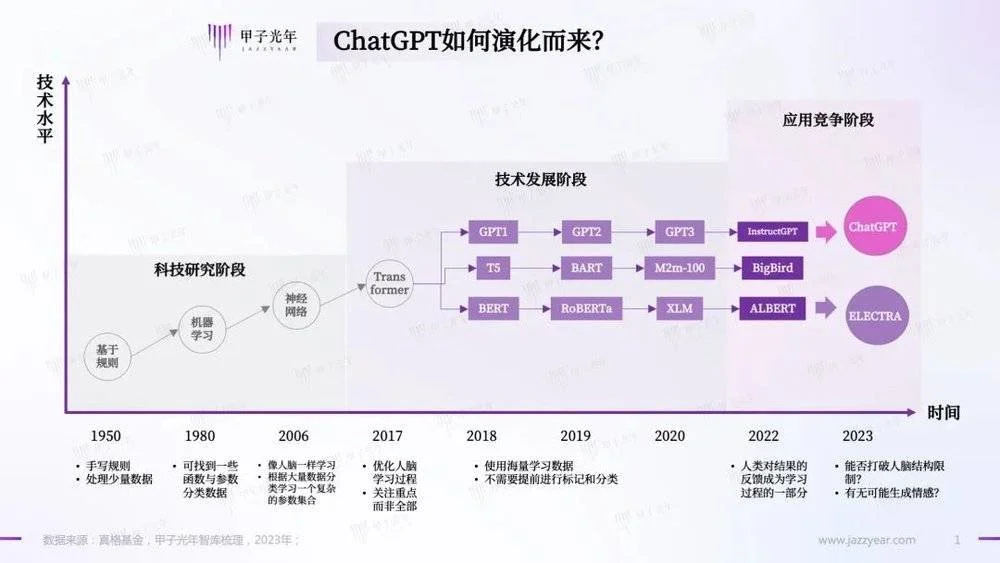
在2015年之前,人工智能基本是小模型的天下。
過去的微軟小冰、蘋果Siri、智能音箱,以及各個平臺的客服機器人背後都是小模型,在其系統中包含若幹Agent(知行主體,可以理解為執行具體任務的程序),一個專門負責聊天對話、一個專門負責詩詞生成、一個專門負責代碼生成、一個專門負責營銷文案等等。
如果需要增加新功能,隻需要訓練一個新的Agent。如果用戶的問題超出既有Agent的范圍,那麼就會從人工智能變為人工智障。
但是ChatGPT不再是這種模式,而是采用“大模型+Prompting(提示詞)”。大模型可以理解為背後隻有一個Agent來解決用戶所有的問題,因此更加接近AGI(通用人工智能)。
ChatGPT的出現不亞於在人工智能行業投下一枚“核彈”。前微軟CEO比爾·蓋茨對ChatGPT評價為“不亞於互聯網誕生”,現微軟CEO薩提亞·納德拉將其盛贊為“堪比工業革命”。如今,有越來越多的公司開始將ChatGPT融入其產品中,或者推出類ChatGPT的產品。
對此,ChatGPT是如何做到的?
二、OpenAI纏鬥Google
ChatGPT背後的公司為OpenAI,成立於2015年,由特斯拉CEO埃隆·馬斯克、PayPal聯合創始人彼得·蒂爾、Linkedin創始人裡德·霍夫曼、創業孵化器Y Combinator總裁阿爾特曼(Sam Altman)等人出資10億美元創立。
OpenAI的誕生旨在開發通用人工智能(AGI)並造福人類。
當時,Google才是人工智能領域的最強公司。2016年打敗人類圍棋冠軍的阿爾法狗背後的AI創企DeepMind,就是被Google收購。
這一年5月,GoogleCEO桑德·皮查伊(Sundar Pichai)宣佈將公司策略從“移動為先”轉變成“人工智能為先”(AI First),並計劃在公司的每一個產品上都應用機器學習算法。
OpenAI誕生的初衷,部分原因就是為避免Google在人工智能領域形成壟斷。OpenAI起初是一個非營利組織,但在2019年成立OpenAI LP子公司,目標是盈利和商業化,並引入微軟的10億美元投資。前YC孵化器總裁阿爾特曼就是此時加入OpenAI擔任CEO。
ChatGPT名字中的GPT(Generative Pre-trained Transformer ,生成式預訓練變換器),是OpenAI推出的深度學習模型。ChatGPT就是基於GPT-3.5版本的聊天機器人。
GPT的名字中包含大名鼎鼎的Transformer,這是由Google大腦團隊在2017年的論文《Attention is all you need》中首次提出的模型。現在來看,這是人工智能發展的裡程碑事件,它完全取代以往的RNN(循環神經網絡)和CNN(卷積神經網絡)結構,先後在NLP(自然語言處理)、CV(計算機視覺)領域取得驚人的效果。
最初的Transformer模型有6500個可調參數,是當時最先進的大語言模型(Large Language Model, LLM)。Google公開模型架構,任何人都可以用其搭建類似架構的模型,並結合自己手上的數據進行訓練。
特斯拉自動駕駛,預測蛋白質結構的AlphaFold2模型,以及本文的主角OpenAI的GPT,都是在Transformer的基礎上構建的。正如它的中文名字一樣——變形金剛。
Transformer出現之後,很多公司基於Transformer做NLP模型研究,其中OpenAI與Google就是最重要的兩傢。
2018年,OpenAI推出1.17億參數的GPT-1,Google推出3億參數的BERT,雙方展開一場NLP的較量。
GPT與BERT采用不同的技術路線。簡單理解,BERT是一個雙向模型,可以聯系上下文進行分析,更擅長“完形填空”;而GPT是一個單向模型,隻能從左到右進行閱讀,更擅長“寫作文”。
兩者的表現如何呢?發佈更早的GPT-1贏初代Transformer,但輸給晚4個月發佈的BERT,而且是完敗。在當時的競賽排行榜上,閱讀理解領域已經被BERT屠榜。此後,BERT也成為NLP領域最常用的模型。
但是這場AI競爭才剛剛開始。OpenAI既沒有認輸,也非常“頭鐵”。雖然GPT-1效果不如BERT,但OpenAI沒有改變策略,而是堅持走“大模型路線”。
在OpenAI眼中,未來的通用人工智能應該長這個樣子:“有一個任務無關的超大型LLM,用來從海量數據中學習各種知識,這個LLM以生成一切的方式,來解決各種各樣的實際問題,而且它應該能聽懂人類的命令,以便於人類使用。”
換句話說,就是大力出奇跡!
接下來的兩年(2019年、2020年),在幾乎沒有改變模型架構的基礎上,OpenAI陸續推出參數更大的迭代版本GPT-2、GPT-3,前者有15億參數,後者有1750億參數。
GPT-2在性能上已經超過BERT,到GPT-3又更進一步,幾乎可以完成自然語言處理的絕大部分任務 ,例如面向問題的搜索、閱讀理解、語義推斷、機器翻譯、文章生成和自動問答,甚至還可以依據任務描述自動生成代碼。
GPT-3大獲成功。OpenAI在早期測試結束後開始嘗試對GPT-3進行商業化,付費用戶可以通過API使用該模型完成所需語言任務,比如前文提到的AI繪畫獨角獸Jasper就是GPT-3的客戶。
值得一提的是,這個過程中Google也在不斷推出新的模型。但不同於OpenAI“從一而終”地堅持GPT路線,Google在BERT之後也推出T5、Switch Transformer等模型,類似於賽馬機制。
此時距離ChatGPT的誕生還差一步。
三、意料之外的走紅
在GPT-3發佈之後,OpenAI研究人員在思考如何對模型進行改進。
他們發現,要想讓GPT-3產出用戶想要的東西,必須引入“人類反饋強化學習機制”(RLHF),通過人工標註對模型輸出結果打分建立獎勵模型,然後通過獎勵模型繼續循環迭代。
而聊天機器人就是引入強化學習的最佳方式,因為在聊天過程中,人類的對話就即時、持續地向模型反饋數據,從而讓模型根據反饋結果進行改進。因為加入人工標註環節,OpenAI為此雇傭大約40位外包人員來與機器人對話。
通過這樣的訓練,OpenAI獲得更真實、更無害,並且更好地遵循用戶意圖的語言模型InstructGPT,在2022年3月發佈,並同期開始構建InstuctGPT的姊妹模型——ChatGPT。
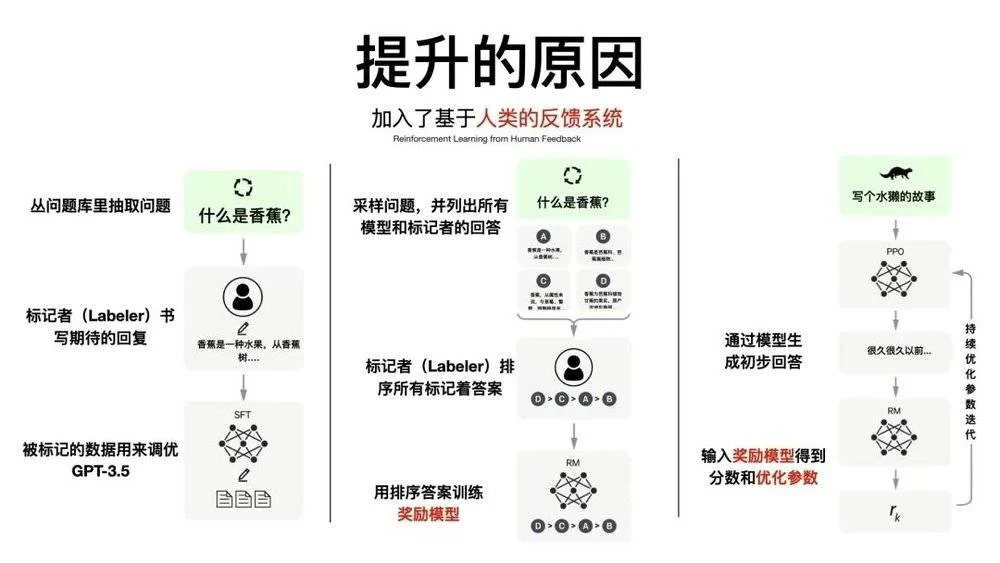
圖片來源真格基金
根據《財富》雜志報道,當ChatGPT準備就緒後,OpenAI一開始並沒有想把它向公眾開放,而是先讓測試人員使用。
但根據OpenAI聯合創始人兼現任總裁Greg Brockman的說法,這些測試人員不清楚應該與這個聊天機器人談論什麼。後來,OpenAI試圖將ChatGPT轉向特定領域的專業人士,但缺乏專業領域的訓練數據。
OpenAI最終不得不決定將ChatGPT向公眾開放。“我承認,我不知道這是否會奏效。” Brockman說。
在《紐約時報》的報道中,OpenAI發佈ChatGPT還有另外一個理由:擔心對手公司可能會在GPT-4 前發佈他們的人工智能聊天機器人,因此要搶先發佈。
總之,在2022年11月30日這天,ChatGPT誕生。
ChatGPT成為史上躥紅最快的應用。發佈第五天,ChatGPT就積累100萬用戶,這是Facebook花10個月才達到的成績;發佈兩個月,ChatGPT突破1億用戶,對此TikTok用大約九個月,Instagram用兩年多。
ChatGPT的迅速傳播連OpenAI也猝不及防,OpenAI首席技術官Mira Murati說:“這絕對令人驚訝。”在舊金山VC活動上OpenAI CEO阿爾特曼說,他“本以為一切都會少一個數量級,少一個數量級的炒作”。
值得一提的是,OpenAI並非唯一的大模型聊天機器人。2021年5月,Google也發佈專註於生成對話的語言模型LAMDA,但直到現在Google仍未對外“交卷”。本周Google匆忙發佈的用於對抗ChatGPT的聊天機器人Bard就由LaMDA提供支撐,但Bard的上線日期也未公佈。
在這場OpenAI與Google持續數年的大模型競爭中,Google最終落下風。
四、代價是什麼?
但ChatGPT的成功,也讓OpenAI付出代價,“燒錢”的代價。
過去幾年,大模型儼然成為一場AI的軍備競賽。在2015年至2020年期間,用於訓練大模型的計算量增加6個數量級,在手寫、語音和圖像識別、閱讀理解和語言理解方面超過人類性能基準。
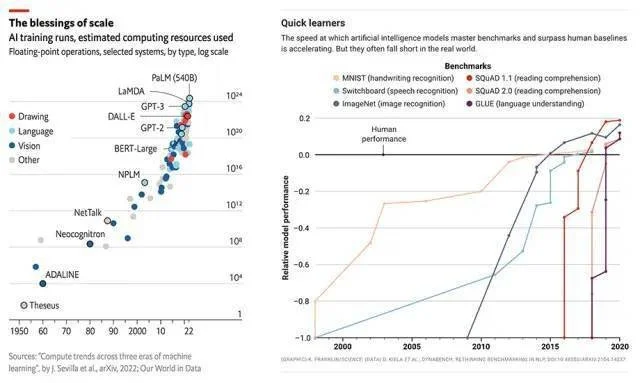
圖片來自紅杉資本
OpenAI的成功讓人們見識到大模型的威力,但是大模型的成功可能難以復制,因為太燒錢。
OpenAI很早就意識到,科學研究要想取得突破,所需要消耗的計算資源每3~4個月就要翻一倍,資金也需要通過指數級增長獲得匹配。而且,AI人才的薪水也不便宜,OpenAI首席科學傢Ilya Sutskever在實驗室的頭幾年,年薪為190萬美元。
OpenAI CEO阿爾特曼在2019年對《連線》雜志表示:“我們要成功完成任務所需的資金比我最初想象的要多得多。”
這也是OpenAI從非營利性組織成立商業化公司的原因。2019年7月,重組後的OpenAI獲得微軟的10億美元投資,可借助微軟的Azure雲服務平臺解決商業化問題,緩解高昂的成本壓力。
解決糧草問題的OpenAI,開始全力訓練大模型。
大模型背後離不開大數據、大算力。GPT-2用於訓練的數據取自於Reddit上高贊的文章,數據集共有約800萬篇文章,累計體積約40G;GPT-3模型的神經網絡是在超過45TB的文本上進行訓練的,數據相當於整個維基百科英文版的160倍。
在算力方面,GPT-3.5在微軟Azure AI超算基礎設施(由V100GPU組成的高帶寬集群)上進行訓練,總算力消耗約3640PF-days(即每秒一千萬億次計算,運行3640天)。
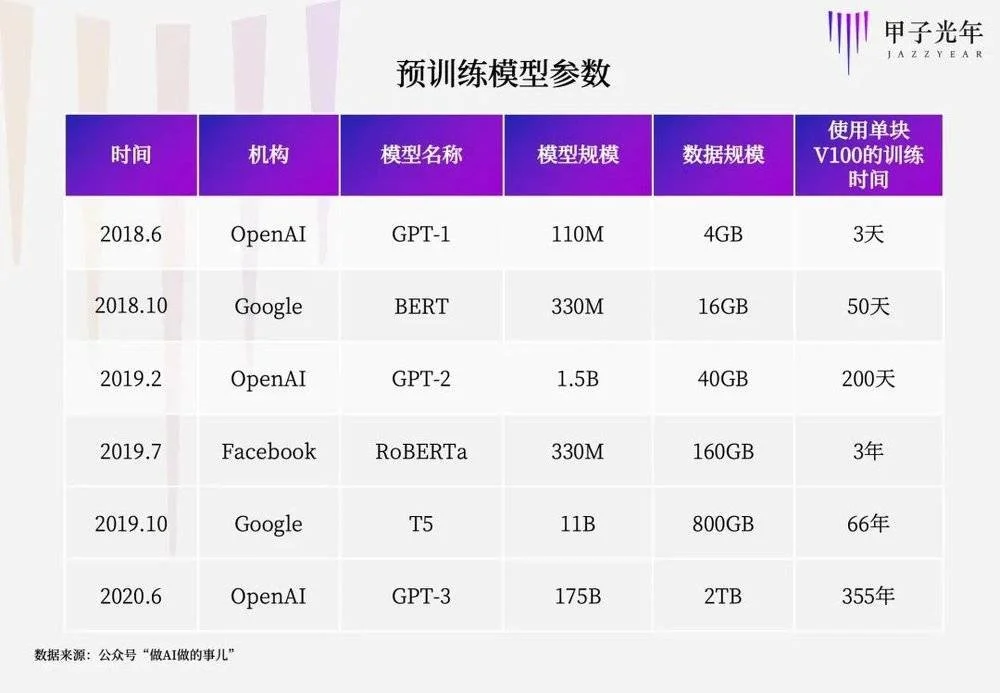
可以說,大模型的訓練就是靠燒錢燒出來的。據估算,OpenAI的模型訓練成本高達1200萬美元,GPT-3的單次訓練成本高達460萬美元。
根據《財富》雜志報道的數據,2022年OpenAI的收入為3000萬美元的收入,但凈虧損總額預計為5.445億美元。阿爾特曼在Twitter上回答馬斯克的問題時表示,在用戶與ChatGPT的每次交互中OpenAI花費的計算成本為“個位數美分”,隨著ChatGPT變得流行,每月的計算成本可能達到數百萬美元。
大模型高昂的訓練成本讓普通創業公司難以為繼,因此參與者基本都是的科技巨頭。
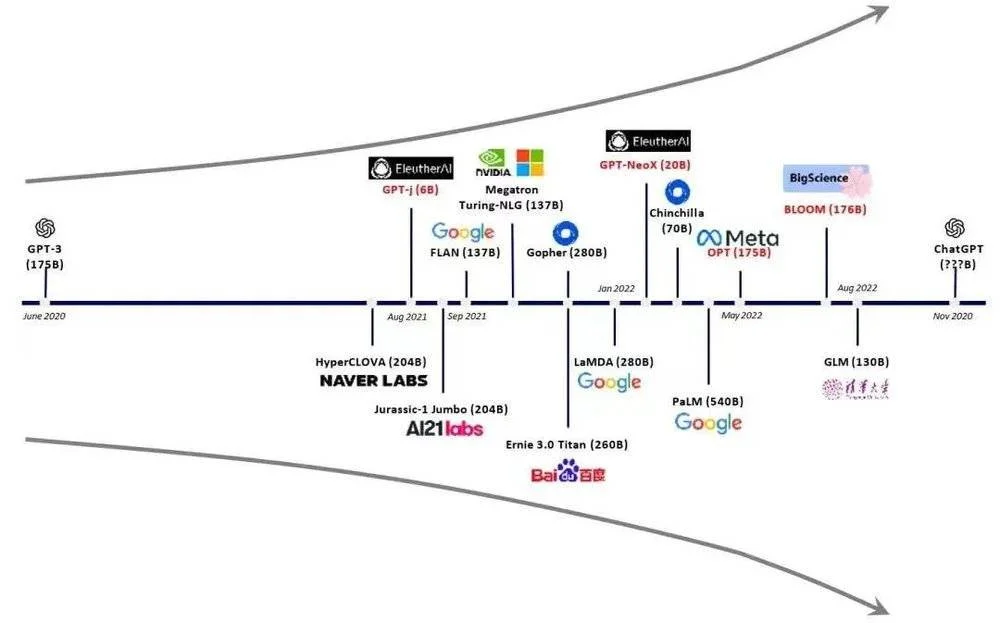
圖片來自陳巍博士
在國內科技公司中,阿裡巴巴達摩院在2020年推出M6大模型,百度在2021年推出文心大模型,騰訊在2022年推出混元AI大模型。
一個需要明確的事實是,雖然OpenAI的大模型取得成功,但模型並非絕對意義上的越大越好,參數量也隻是影響最終模型性能的因素之一。
GPT-3也不是參數最大的模型,比如,由英偉達和微軟開發的Megatron-Turing NLG模型,擁有超過5000億個參數,但在性能方面並不是最好的,因為模型未經充分訓練。
實際上,在特定場景下,較小的模型可以達到更高的性能水平,而且成本更低。
一位AI從業者告訴“甲子光年”:“現實就是,NLP公司做to B隻能做小模型。得私有化,工程性能好,計算消耗少。甲方還希望你能部署在CPU上呢。”
關於大模型與小模型的關系,我們會在後面的文章中繼續討論。
五、錢都流向哪裡?
以ChatGPT為代表的生成式AI正在引發新一輪AI軍備競賽,這個特別燒錢的新興市場,也讓背後的基礎設施廠商賺得盆滿缽滿。
著名風投機構A16Z將生成式AI市場分成三層:
應用層:將第三方API或自有模型集成到面向用戶的產品中,比如AI繪畫應用Jasper、Midjourney;
模型層:為應用層提供能力,比如閉源的GPT-3,或者開源的Stable diffusion;
基礎設施層:為生成人工智能模型運行培訓和推斷工作負載的雲平臺和硬件制造商。
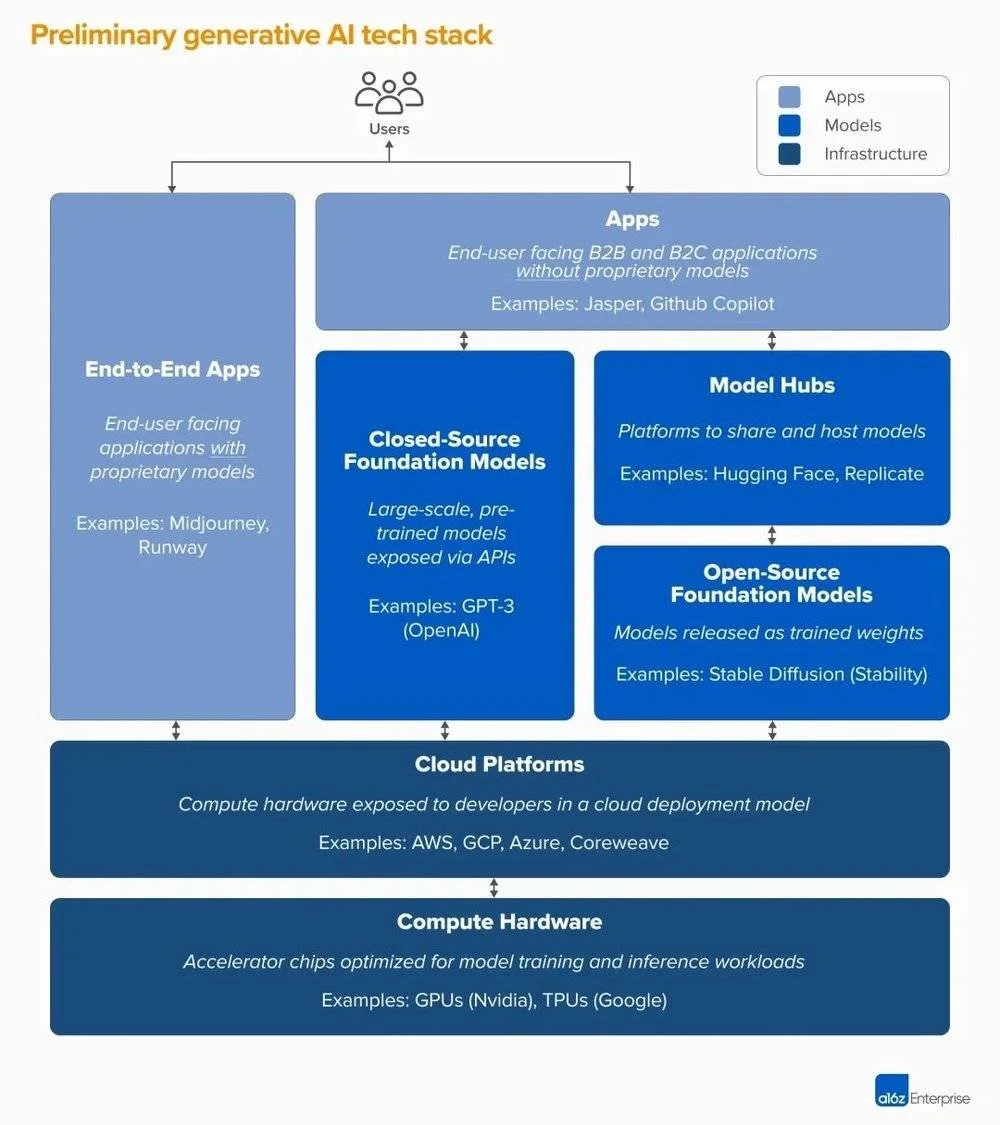
圖片來自A16Z
生成式AI的大量資金最終都穩定地流向基礎設施層——以亞馬遜AWS、微軟Azure、GoogleGCP為主的雲廠商,以及以英偉達為代表的GPU廠商。
據A16Z估計,應用層廠商將大約20%~40%的收入用於推理和模型微調,這部分收入通常直接支付給雲廠商或第三方模型提供商,第三方模型提供商也會將大約一半的收入用於雲基礎設施。因此,總的來看生成式AI總收入的10%~20%都流向雲提供商。
微軟投資OpenAI就是一個很好的案例。
2019年微軟投資OpenAI 10億美元,其中大約一半以Azure雲計算的代金券形式,成為OpenAI 技術商業化的“首選合作夥伴”,未來可獲得OpenAI 的技術成果的獨傢授權。今年1月23日,微軟再次加碼,宣佈向OpenAI追求數十億美元,來加速人工智能的突破。
根據《財富》雜志報道,在OpenAI的第一批投資者收回初始資本後,微軟將有權獲得OpenAI 75%的利潤直到收回投資成本;當OpenAI賺取920億美元的利潤後,微軟的份額將降至49%。與此同時,其他風險投資者和 OpenAI的員工也將有權獲得OpenAI 49%的利潤,直到他們賺取約1500億美元。如果達到這些上限,微軟和投資者的股份將歸還給OpenAI的非營利基金會。
本質上,OpenAI是在把公司借給微軟,借多久取決於OpenAI賺錢的速度。微軟對OpenAI的投資更大的野心在於,希望在下一個人工智能的十年向Google以及其他科技巨頭發起挑戰。
在今年1月份的瑞士達沃斯論壇期間,微軟CEO納德拉表示,微軟將全線接入ChatGPT,計劃將ChatGPT、DALL-E等人工智能工具整合進微軟旗下的所有產品中,包括且不限於Bing搜索引擎、Office全傢桶、Azure雲服務、Teams聊天程序等等。
本周,新版Bing正式發佈。納德拉霸氣表示:“比賽今天開始,我們將繼續前進並快速行動,希望在搜索領域再次獲得更多創新的樂趣。”
除微軟之外,英偉達則是生成式AI幕後最大的贏傢。
雲廠商每年總共花費超過1000億美元的資本支出,來確保他們能夠擁有最全面、最可靠和最具成本競爭力的平臺,比如獲得英偉達最先進、也是最稀缺的GPU——A100與H100。GPU成為生成式AI發展上限“卡脖子”的一環。
英偉達過去一個月的股價漲幅甚至超過微軟。
ChatGPT在科技圈引發的震動仍在持續。一個不可否認的事實是,國內的AI公司多少處於一種置身之外的感受。人們驚嘆於技術的進步,也感慨於實力的差距。
對此,雲知聲創始人黃偉如此評價:
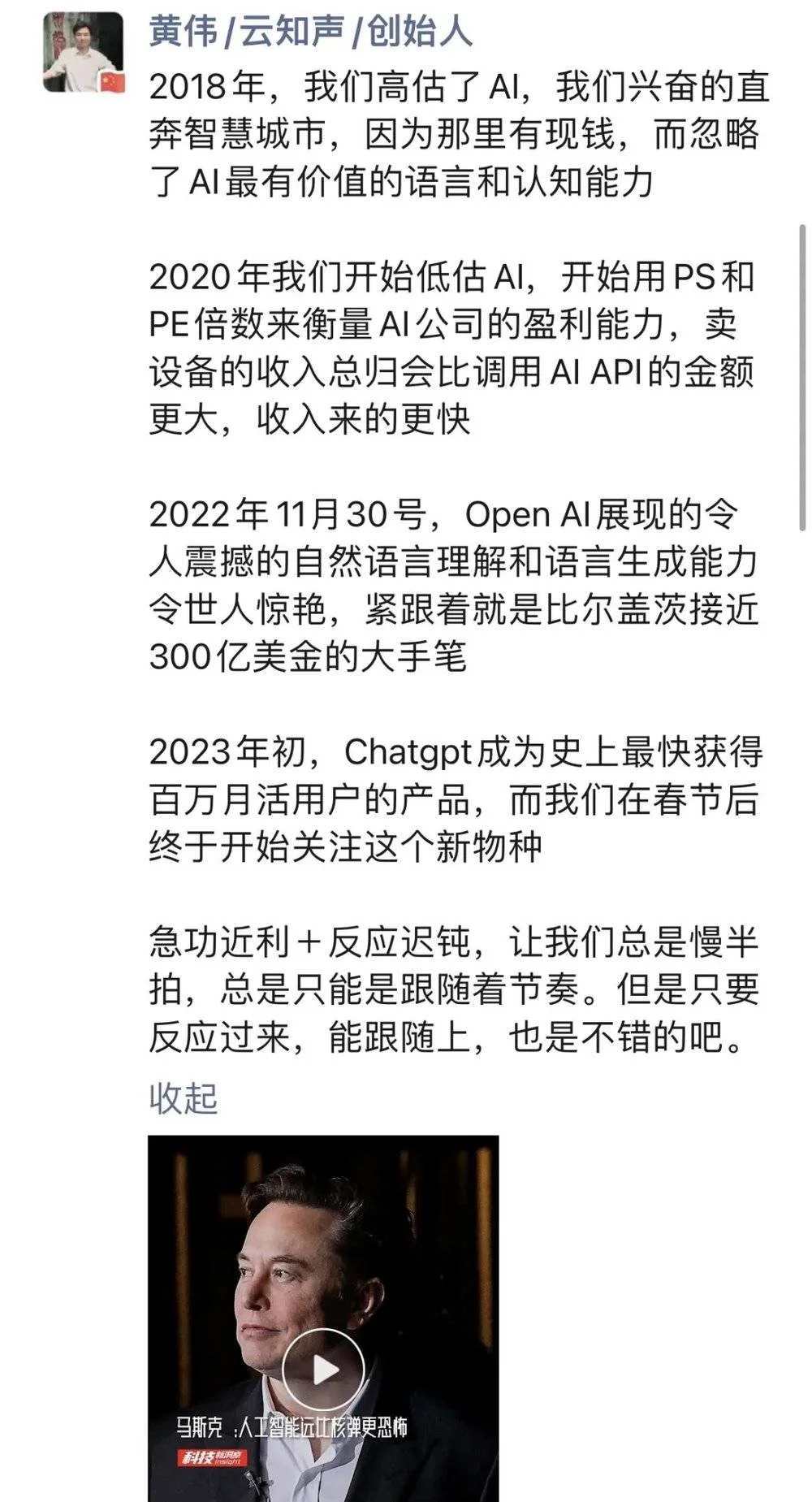
圖源:朋友圈截圖
接下來,國內科技公司會如何接招呢?