當地時間周五(2月25日),Facebook母公司Meta首席執行官紮克伯格最新推出“Meta人工智能大型語言模型”(LargeLanguageModelMetaAI),簡稱“LLaMA”。

紮克伯格在社交媒體上稱,Facebook AI Research研發的LLaMA是“目前水平最高的”大型語言模型,目標是幫助研究人員推進他們在人工智能(AI)領域的工作。
“大型語言模型”(LLM)可以消化大量的文本數據,並推斷文本的單詞之間的關系。隨著計算能力的進步,以及輸入數據集與參數空間的不斷擴大,LLM的能力也相應提高。
目前,LLM已經被證明能高效地執行多種任務,包括文本生成、問題回答、書面材料總結等。紮克伯格稱,LLM在自動證明數學定理、預測蛋白質結構等更復雜的方面也有很大的發展前景。
值得一提的是,近期大火的ChatGPT就是采用LLM構建的聊天機器人。ChatGPT由GPT3.5提供支持,而GPT3.5是一款基於OpenAI 175B參數基礎模型訓練的LLM,175B是它從訓練數據中所學習、沉淀下來的內容。
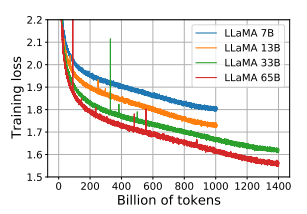
Meta在官網介紹中稱,LLaMA有7B、13B、33B和65B四個基礎模型,在大多數基準測試中都優於GPT3.5的前身GPT3-175B,而LLaMA-65B可與業內最佳的Chinchilla-70B和PaLM-540B競爭。
Meta還宣佈,將針對學術研究者共享其模型,正在接受研究人員的申請。與之截然不同的是,Google旗下的DeepMind和OpenAI並不公開訓練代碼。
根據2021年媒體的一份調查顯示,AI專傢們通常將DeepMind、OpenAI和FAIR(Facebook AI Research)視為該領域的“前三甲”。
去年年底,Meta發佈另一款名為Galactica的模型,但因經常分享偏見和不準確的信息而遭到下架。