OpenAI機器人理解力雖強,卻無法進行非語言交流。最近,哥倫比亞大學華人團隊打造全新的機器人Emo,不僅可以提前預測和模擬人類表情,還可以進行眼神交流。此前,人形機器人Ameca“大夢初醒”的神情,已讓許多人感受到真正的“恐懼”。


隨著ChatGPT橫空出世,得到加持的人形機器人雖擅長語言交流,但是在非語言交流,特別是面部表情,還差得很遠。

未來,如果人類真的要生活在一個充滿機器人的世界之中,機器人必須要有像人類一樣能自主通過面部表情獲取人類的信任的能力。
顯然,設計一款不僅能做出各種面部表情,還能知道何時表現的機器人,一直是一項艱巨的任務。
來自哥倫比亞大學工程學院的創新機器實驗室,5年來一直致力於這一挑戰。
最近,研究團隊推出一款機器人Emo——能夠預測人類面部表情,並與人類同時做出表情。
最新研究已發表在Science子刊上。

論文地址:https://www.science.org/doi/10.1126/scirobotics.adi4724
Emo的自我監督學習框架,就像人類照鏡子來練習面部表情。

有趣的是,Emo甚至學會在一個人微笑前840毫秒提前預測,並同時與人類一起微笑。

這種快速及時的表情回應,能讓人類感受到機器人的真誠和被理解的感覺。
而且,它還可以做出眼神互動。

Emo如何能夠做到精準預測人類表情?
人機交互革命正來臨
由Hod Lipson帶領的研究團隊稱,在開發機器人Emo之前,需要解決兩大挑戰。
首先是硬件方面,如何機械地設計一個涉及復雜硬件和驅動機制,且具有表現力的多功能機器人人臉。
另一方面,就是設計好的機器人臉,需要知道生成哪種表情,讓其看起來自然、及時和真實。

而且更進一步,研究小組還希望訓練機器人能夠預測人類的面部表情,並與人同時做出這些表情。
具體來說,Emo臉部配備26個執行器,可以呈現出多種多樣的微妙面部表情。
在執行器之外,Emo的臉使用矽膠皮設計,方便快速定制和維護。

為進行更加逼真的互動,研究人員為機器人的眼睛配備高分辨率攝像頭。
因此Emo還可以做到眼神交流,這也是非語言交流中重要的一部分。
此外,研究小組還開發兩個人工智能模型:一個是通過分析目標面部的細微變化來預測人類的面部表情,另一個使用相應的面部表情生成運動指令。
為訓練機器人如何做出面部表情,研究人員將Emo放在相機前,讓它做隨機的動作。
幾個小時後,機器人學會他們的面部表情和運動指令之間的關系。

團隊將其稱為“自我建模”,與人類想象自己做出特定表情的樣子。
然後,研究小組為Emo播放人類面部表情的視頻,通過逐幀觀察並學習。
經過幾個小時的訓練後,Emo可以通過觀察人們面部的微小變化,來預測他們的面部表情。
這項研究主要作者Yuhang Hu表示,“我認為,準確預測人類面部表情是人機交互(HRI)的一場革命。傳統上,機器人的設計並不考慮人類在交互過程中的表情”。

“現在,機器人可以整合人類的面部表情作為反饋。當機器人與人實時進行共同表達時,不僅提高交互質量,還有助於在人類和機器人之間建立信任。未來,在與機器人互動時,它會像真人一樣,觀察和解讀你的面部表情”。
接下來,一起看看Emo背後設計的具體細節。
技術介紹
機械控制結構


Emo 配備26個執行器(下圖),提供更高的面部自由度,可以做出不對稱的面部表情。
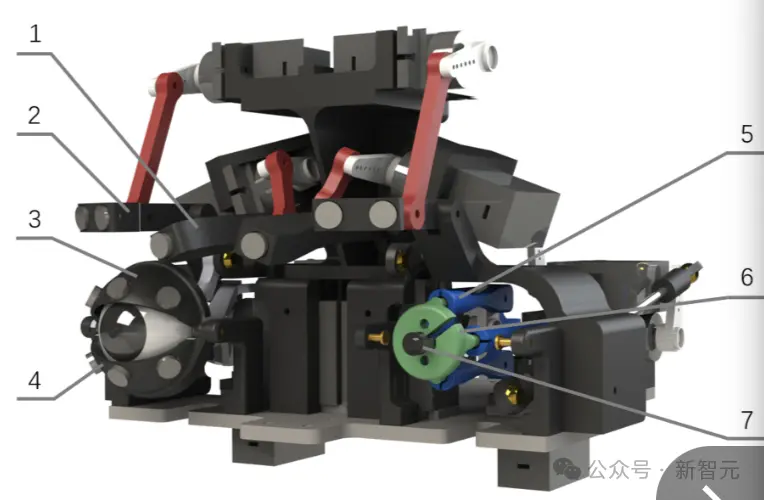
(1 和 2) 用磁鐵連接的連桿控制眉毛。(3) 上眼瞼。(4) 下眼瞼。(5) 眼球連桿。(6) 眼球框架。(7) 相機

(8至10和13) 口形被動連桿機構。(11 和 12)二維五桿機制(2D five-bar mechanism)的連桿。
Emo設計的主要區別之一是使用直接連接的磁鐵來使可更換的面部皮膚變形。這種方法可以更精確地控制面部表情。
此外,Emo的眼睛內嵌攝像頭,可實現仿人視覺感知。

這些高分辨率的 RGB(紅、綠、藍)攝像頭,每隻眼睛的瞳孔內都有一個,增強機器人與環境互動的能力,並能更好地預測對話者的面部表情。
眼睛模塊控制眼球、眉毛和眼瞼的運動,如上圖所示。
每個眼框都裝有一個高分辨率 RGB 攝像頭。眼框分別由兩個電機通過平行四邊形機構在俯仰和偏航兩個軸上驅動。
這種設計的優點是在眼框中央創造更多空間,使研究人員能夠將攝像頭模塊安裝在與人類瞳孔相對應的自然位置。
這種設計有利於機器人與人類進行更自然的面對面互動。
它還能實現正確自然的註視,這是近距離非語言交流的一個關鍵元素。

除這些硬件升級外,研究人員還引入一個由兩個神經網絡組成的學習框架——一個用於預測Emo自身的面部表情(自我模型),另一個用於預測對話者的面部表情(對話者模型)。
研究人員的軟皮人臉機器人有23個專用於控制面部表情的電機和3個用於頸部運動的電機。
整個面部皮膚由矽膠制成,並用30塊磁鐵固定在機器人面部之上。
機器人面部皮膚可以更換成其他設計,以獲得不同的外觀和皮膚材質。

表情生成模型
研究人員還提出一個升級版逆向模型,可使機器人在相同的計算硬件上生成電機指令的速度比上一代產品快五倍以上。
他們提出一種自我監督學習過程,以訓練研究人員的面部機器人在沒有明確的動作編排和人類標簽的情況下生成人類面部表情。
控制機器人的傳統方法依賴於運動學方程和模擬,但這隻適用於具有已知運動學的剛體機器人。
機器人有柔軟的可變形皮膚和幾個帶有四個套筒關節的被動機構,因此很難獲得機器人運動學的運動方程。
研究人員利用基於視覺的自我監督學習方法克服這一難題,在這種方法中,機器人可以通過觀察鏡子中的自己來學習運動指令與所產生的面部表情之間的關系。
機器人的面部表情由19個電機控制,其中18個電機對稱分佈,一個電機控制下頜運動。
在研究人員的案例中,面部數據集中的表情都是對稱的;
因此,對稱分佈的電機在控制機器人時可以共享相同的電機指令。
因此,實際的控制指令隻需要11個歸一化為 [0, 1] 范圍的參數。
面部反演模型是利用機器人自身生成的數據集(下圖)進行訓練的,其中包括電機指令和由此產生的面部地標。

研究人員以自我監督的方式,通過隨機的 “電機咿呀學語 ”過程收集數據。在將指令發送到控制器之前,該過程會自動刪除可能會撕裂面部皮膚或導致自碰撞的電機指令。
在伺服電機到達指令定義的目標位置後,研究人員使用RGB攝像頭捕捉機器人的面部圖像,並提取機器人的面部地標。
通過將自我模型和預測對話者模型相結合,機器人可以執行協同表達。
表情預測模型
研究人員還開發一個預測模型,它可以實時預測對話者的目標面部表情。
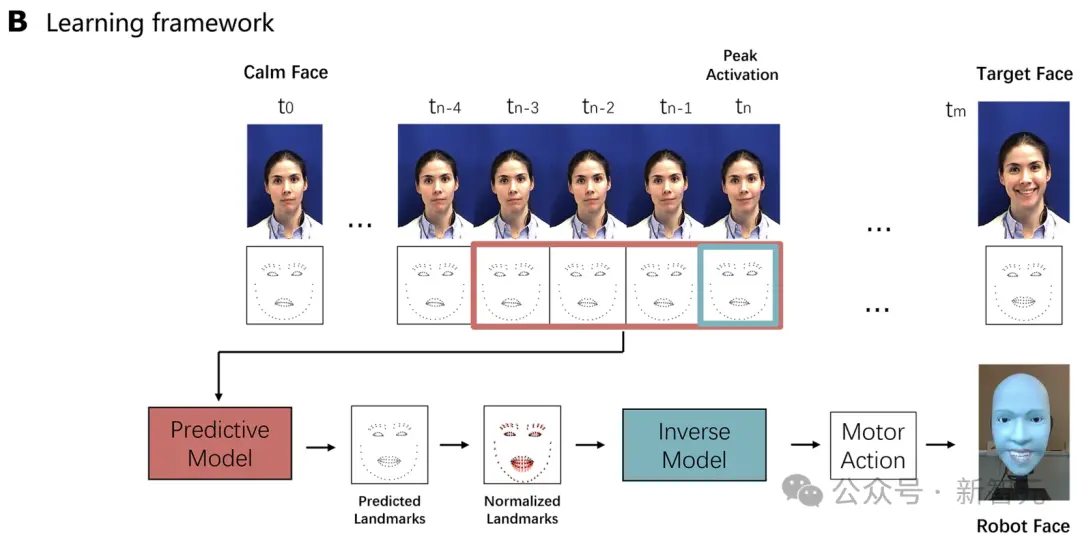
為使機器人能及時做出真實的面部表情,它必須提前預測面部表情,使其機械裝置有足夠的時間啟動。
為此,研究人員開發一個預測面部表情模型,並使用人類表情視頻數據集對其進行訓練。該模型能夠根據一個人面部的初始和細微變化,預測其將要做出的目標表情。
首先,研究人員使用每組面部地標與每個視頻中初始(“靜止”)面部表情的面部地標之間的歐氏距離來量化面部表情動態。
研究人員將靜止面部地標定義為前五幀的平均地標,目標面部地標則定義為與靜止面部地標差異最大的地標。
靜態面部地標的歐氏距離與其他幀的地標的歐氏距離會不斷變化,並且可以區分。
因此,研究人員可以通過地標距離相對於時間的二階導數來計算表情變化的趨勢。
研究人員將表情變化加速度最大時的視頻幀作為 “激活峰值”。
為提高準確性並避免過度擬合,研究人員通過對周圍幀的采樣來增強每個數據。
具體來說,在訓練過程中,預測模型的輸入是從峰值激活前後總共九幀圖像中任意抽取四幀圖像。
同樣,標簽也是從目標臉部之後的四幀圖像中隨機取樣的。
數據集共包含45名人類參與者和970個視頻。其中80%的數據用於訓練模型,其餘數據用於驗證。
研究人員對整個數據集進行分析,得出人類通常做出面部表情所需的平均時間為0.841 ± 0.713秒。
預測模型和逆向模型(僅指研究人員論文中使用的神經網絡模型的處理速度)在不帶 GPU 設備的 MacBook Pro 2019上的運行速度分別約為每秒 650 幀(fps)和 8000 幀(fps)。
這一幀頻還不包括數據捕獲或地標提取時間。
研究人員的機器人可以0.002秒內成功預測目標人類面部表情並生成相應的電機指令。這一時間留給捕捉面部地標和執行電機指令以在實體機器人面部生成目標面部表情的時間約為0.839秒。
為定量評估預測面部表情的準確性,研究人員將研究人員的方法與兩個基線進行比較。
第一種基線是在逆模型訓練數據集中隨機選擇一張圖片作為預測對象。
該基線的數據集包含大量由咿呀學語產生的機器人表情圖片。
第二條基線是模仿基線,它選擇激活峰值處的面部地標作為預測地標。如果激活峰值接近目標臉部,那麼該基線與研究人員的方法相比就很有競爭力。
然而,實驗結果表明,研究人員的方法優於這一基線,表明預測模型通過歸納面部的細微變化,而不是簡單地復制最後輸入幀中的面部表情,成功地學會預測未來的目標面部。
圖4B顯示對預測模型的定量評估。
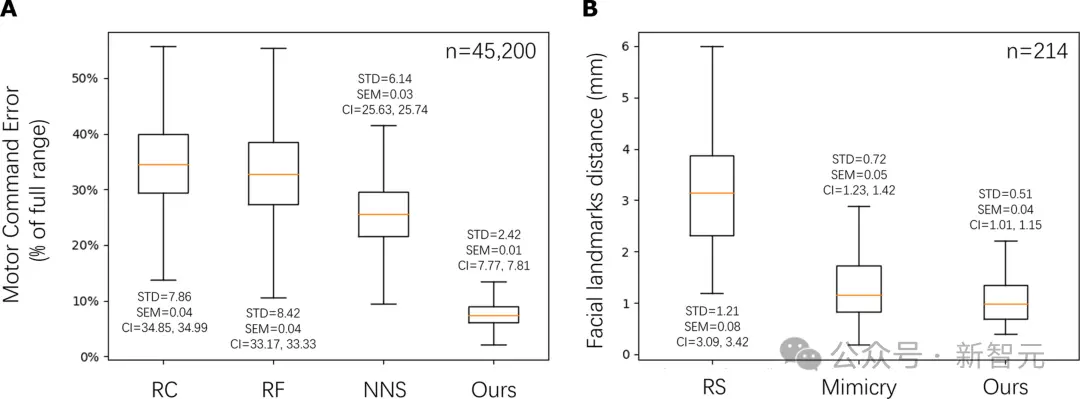
研究人員計算預測地標與地面實況地標之間的平均絕對誤差,地面實況地標由維度為113×2的人類目標面部地標組成。
表格結果(表S2)表明,研究人員的方法優於兩種基線方法,表現出更小的平均誤差和更小的標準誤差。
Emo下一步:接入大模型
有能夠模擬預測人類表情的能力之後,Emo研究的下一步便是將語言交流整合到其中,比如接入ChatGPT這樣的大模型。
隨著機器人的行為能力越來越像人類,團隊也將關註背後倫理問題。
研究人員表示,通過發展能夠準確解讀和模仿人類表情的機器人,我們正在向機器人可以無縫地融入我們的日常生活的未來更近一步,為人類提供陪伴、幫助。
想象一下,在這個世界,與機器人互動就像與朋友交談一樣自然和舒適。