特斯拉備受關註的Dojo超算指令集結構細節史上首次大公開!而且還大秀一把Dojo的數據格式、系統網絡,以及軟件系統繞行死節點的能力。關於特斯拉自研的AI芯片D1,更多細節也被披露。
原標題:特斯拉Dojo超算最新細節大公開!涉及指令集結構、數據格式,還有系統網絡
一切來自剛剛舉辦的矽谷芯片技術研討會HOT CHIPS,聽特斯拉硬件工程師Emil Talpes怎麼說。
特斯拉Dojo超算
所謂Dojo,是特斯拉自研的超級計算機,能夠利用海量的視頻數據,做“無人監管”的標註和訓練。
它有高度可擴展且完全靈活的分佈式系統,能夠訓練神經網絡,還能適應新的算法和應用。

不僅如此,還能從頭開始構建大系統,而不是從現有的小系統演變而來。
每個Dojo ExaPod集成120個訓練模塊,內置3000個D1芯片,擁有超過100萬個訓練節點,算力達到1.1EFLOP*(每秒千萬億次浮點運算)。
微架構方面,每個Dojo節點都有一個內核,是一臺具有CPU專用內存和 I/O接口的成熟計算機。
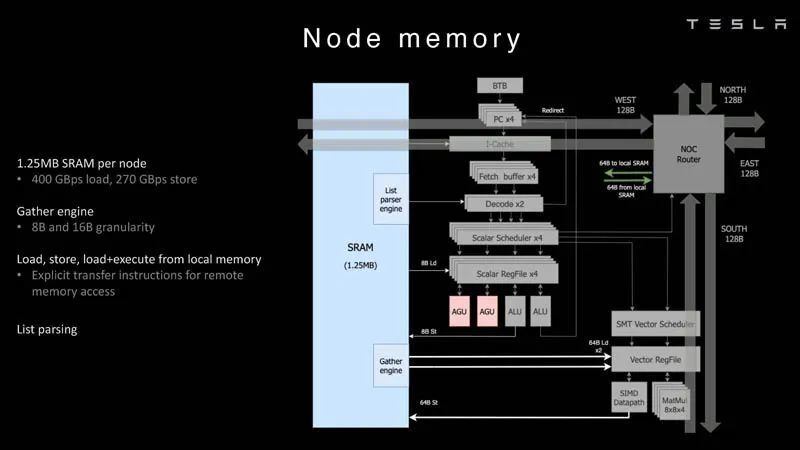
這很重要,因為每個內核都可以做到獨立處理,而不依賴於共享緩存或寄存器文件。
每個內核擁有一個1.25MB的SRAM,這是主存儲器。這種SRAM能以400GB/秒的速度加載,並以270GB/秒的速度存儲。
芯片有明確的指令,可以將數據移入或移出Dojo超算中其他內核的外部SRAM存儲器。

嵌入SRAM中的是列表解析器引擎(list parser engine),諸如此類的引擎可以將信息一起發送到其他節點或從其他節點獲取信息,無需像其他CPU架構一樣。
至於通信接口,每個節點都與2D網格相連,在節點邊界處每周期有八個數據包。而且每個節點都有獨立的網絡連接,能與相鄰節點進行無縫連接。
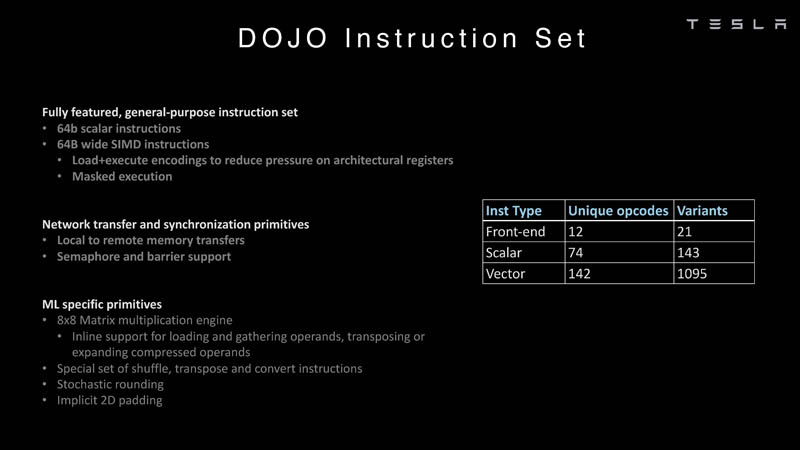
關於Dojo的指令集,它支持64位標量指令和64B SIMD指令,能夠處理從本地到遠程內存傳輸數據的原語(primitives),並支持信號量(semaphore)和屏障約束( barrier constraints)。
特斯拉自研AI芯片新進展
數據格式對AI來說至關重要,特別是芯片所支持的數據格式。
特斯拉借助Dojo超算來研究業界常見的芯片,例如FP32、FP16和BFP16。
FP32格式比AI訓練應用的許多部分所需的精度和范圍更廣,IEEE指定的FP16格式沒有覆蓋神經網絡中的所有處理層。
相反,GoogleBrain團隊創建的Bfloat格式應用范圍更廣,但精度更低。
特斯拉不僅提出用於較低精度和更高矢量處理的8位FP8格式,還提出一組可配置的8位和16位格式,Dojo超算可以在尾數的精度附近滑動,以涵蓋更廣泛的范圍和精度。
在給定時間內,特斯拉最多可以使用16種不同的矢量格式,但每個64B數據包必須屬於同一類型。

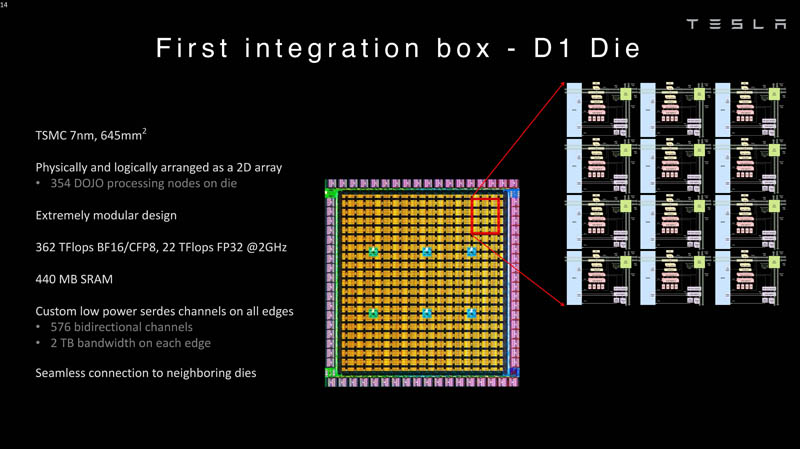
特斯拉自研的D1芯片,是Dojo ExaPod的核心。
由臺積電制造,采用7納米制造工藝,擁有500億個晶體管,芯片面積為645mm²,小於英偉達的A100(826 mm²)和AMD Arcturus(750 mm²)。
每個芯片有354個Dojo處理節點和440MB的靜態隨機存儲器。
D1芯片測試完成後,隨即被封裝到5×5的Dojo訓練瓦片(Tile)上。
這些瓦片每邊有4.5TB/s的帶寬,每個模組還有15kW的散熱能力的封蓋,減掉給40個I/O的散熱,也就是說每個芯片的散熱能力接近600W。
瓦片也包含所有的液冷散熱和機械封裝,這和Cerebras公司推出的WES-2芯片的封裝理念類似。

演講最後結束時,特斯拉工程師Emil Talpes表達如下觀點:
我們最終的目標是追求可擴展性。我們已經不再強調CPU中常見的幾種機制,像是一致性、虛擬內存、全局查找目錄。隻因為當我們擴展到非常大的系統時,這些機制並不能很好地隨之擴展。
相反,在整個網格中我們依靠的是那種快速、分散的SRAM存儲,這樣能夠得到更高數量級的互連速度支持。