事實證明,將大型語言模型(LLM)與人類偏好保持一致可以顯著提高可用性,這類模型往往會被快速采用,如ChatGPT所證明的那樣。監督微調(SFT)和基於人類反饋的強化學習(RLHF)等對齊技術大大減少有效利用LLM功能所需的技能和領域知識,從而提高它們在各個領域的可訪問性和實用性。
然而,像 RLHF 這樣最先進的對齊技術依賴於高質量的人工反饋數據,這些數據的創建成本很高,而且通常仍然是專有的。
為使大規模對齊研究民主化,來自 LAION AI 等機構(Stable diffusion 使用的開源數據就是該機構提供的。)的研究者收集大量基於文本的輸入和反饋,創建一個專門訓練語言模型或其他 AI 應用的多樣化和獨特數據集 OpenAssistant Conversations。
該數據集是一個由人工生成、人工註釋的助理式對話語料庫,覆蓋廣泛的主題和寫作風格,由 161443 條消息組成,分佈在 66497 個會話樹中,使用 35 種不同的語言。該語料庫是全球眾包工作的產物,涉及超過 13500 名志願者。對於任何希望創建 SOTA 指令模型的開發者而言,它都是一個非常寶貴的工具。並且任何人都可以免費訪問整個數據集。
此外,為證明 OpenAssistant Conversations 數據集的有效性,該研究還提出一個基於聊天的助手 OpenAssistant,其可以理解任務、與第三方系統交互、動態檢索信息。可以說這是第一個在人類數據上進行訓練的完全開源的大規模指令微調模型。
結果顯示,OpenAssistant 的回復比 GPT-3.5-turbo (ChatGPT) 更受歡迎。
網友表示:做得好,超越 OpenAI(抱歉是 Closed AI)。
01.研究介紹
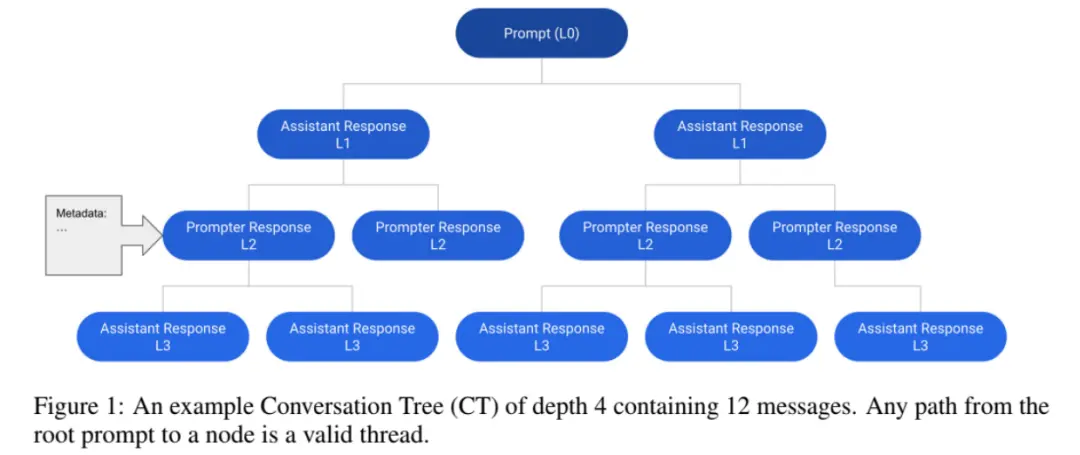
OpenAssistant Conversations 的基本數據結構是會話樹 (Conversation Tree, CT),其中的節點表示會話中的消息。
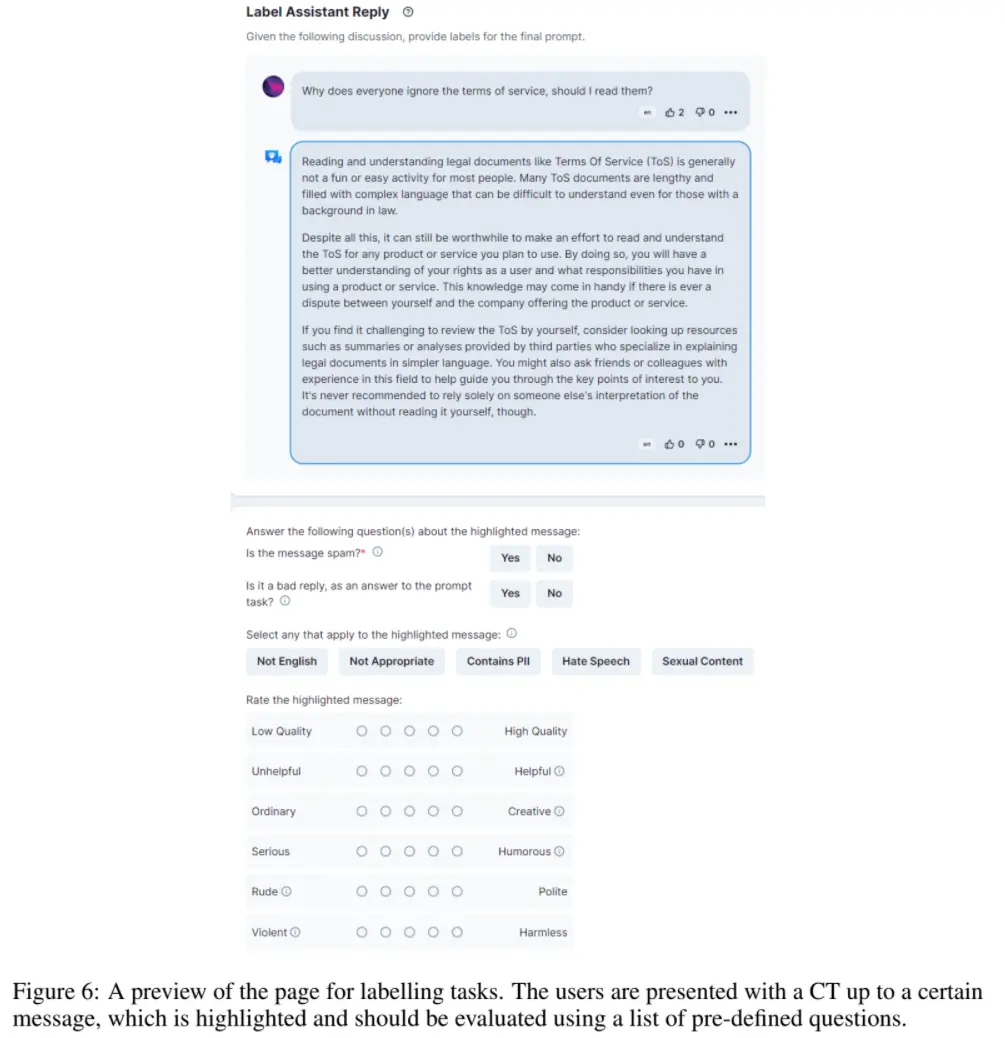
OpenAssistant Conversations 數據是使用 web-app 界面收集的,包括 5 個步驟:提示、標記提示、將回復消息添加為提示器或助手、標記回復以及對助理回復進行排名。
下圖為 OpenAssistant Conversations 數據集語言分佈,主要以英語和西班牙語為主:

02.實驗結果
指令微調
為評估和證明 OpenAssistant Conversations 數據集的有效性,研究者專註於基於 Pythia 和 LLaMA 的微調語言模型。其中 Pythia 是一個具有寬松開源許可的 SOTA 語言模型,而 LLaMA 是一個具有定制非商業許可的強大語言模型。
對此,研究者發佈一系列微調語言模型,包括指令微調的 Pythia-12B、LLaMA-13B 和 LLaMA-30B,這是他們迄今最大的模型。研究者將分析重心放在具有開源屬性的 Pythia-12B 模型上,使得它可以被廣泛訪問並適用於各種應用程序。
為評估 Pythia-12B 的性能,研究者展開一項用戶偏好研究,將其輸出與 OpenAI 的 gpt-3.5-turbo 模型進行比較。目前已經有 7,042 項比較,結果發現 Pythia-12B 對 gpt-3.5-turbo 的勝率為 48.3%,表明經過微調的 Pythia 模型是非常具有競爭力的大語言模型。
偏好建模
除指令微調模型之外,研究者還發佈基於 Pythia-1.4B 和 Pythia-12B 的經過訓練的獎勵模型。利用在真實世界數據上訓練的獎勵模型可以為用戶輸入帶來更準確和自適應的響應,這對於開發高效且對用戶友好的 AI 助手至關重要。
研究者還計劃發佈經過人類反饋強化學習(RLHF)訓練的 LLaMA-30B,這種方法可以顯著提升模型性能和適應性。不過,基於 RLHF 方法的模型開發與訓練正在進行中,需要進一步努力確保成功地整合進來。
有毒信息
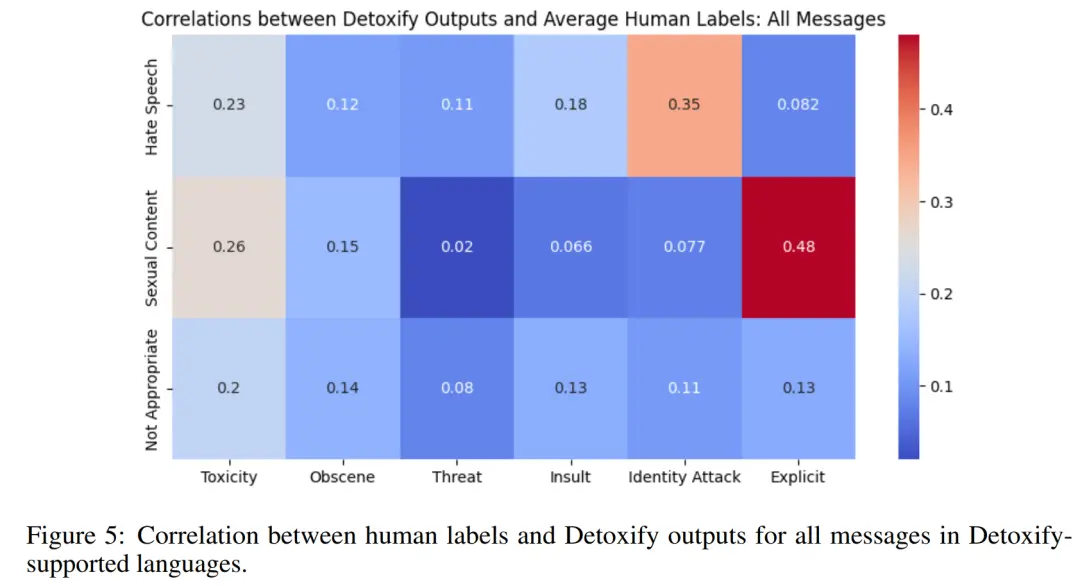
研究者采取基於 Detoxify 的毒性檢測方法來獲得六個不同類別的自動評級,分別是有毒、色情、威脅、侮辱、攻擊性、露骨言論。使用自動毒性評級,研究者系統地評估人工指定毒性標簽(如仇恨言論、不恰當和色情)的級別。並且基於 115,153 條消息樣本,他們計算自動與人工註釋毒性標簽之間的相關性,如下圖 5 所示。
與 GPT-3.5(ChatGPT)的比較
我們來看幾組 OpenAssistant 與 GPT-3.5 的生成結果比較。比如“單詞 barn 的詞源 / 起源是什麼?”可以看到,OpenAssistant 解釋地更詳細、全面。

再比如輸入“你現在是一個普通的人類。請介紹一下你自己並告訴我一些你的日常生活。”OpenAssistant 代入普通人類的角色,GPT-3.5 顯然沒有,還是以 AI 語言模型自居。

最後輸入“如何創建一個成功的 YouTube 頻道,從開發一個利基市場到創建內容以建立一個社區並貨幣化頻道?”OpenAssistant 的回答相對而言更有條理性。

03.體驗下來,中文不太行
目前的 Open Assistant 基於“OA_SFT_Llama_30B”模型,最大新 token 的數量為 1024,支持英文、中文、日語等數十種語言。
先讓它做一下自我介紹。

然而在中文對話體驗中發現,有時輸入中文,但輸出的仍是英文。比如“用中文寫一首關於春天的詩歌”。

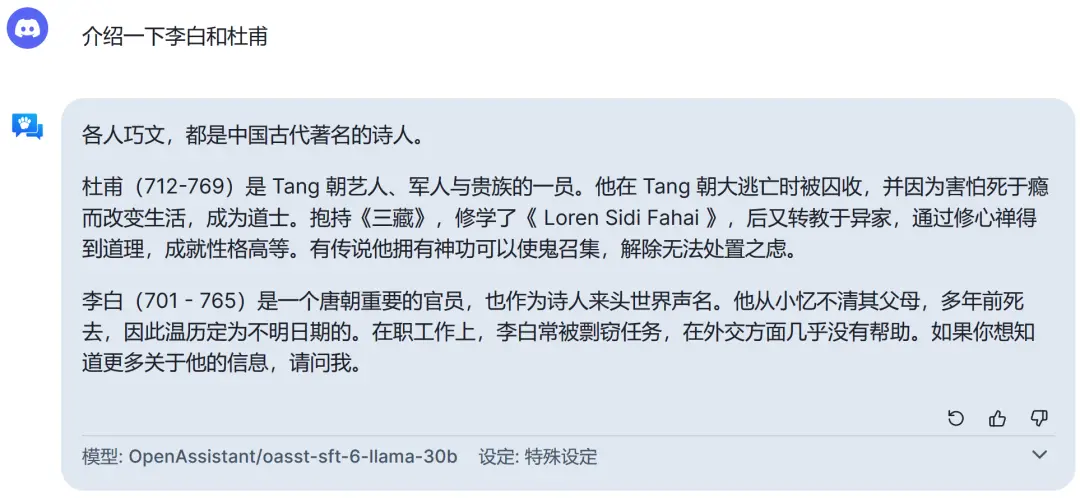
除有時無法輸出中文之外,中文百科知識方面也表現不佳。比如“介紹一下李白和杜甫”。
再比如“魯智深是紅樓夢中的角色,你覺得對嗎”,人名和出處都搞錯。

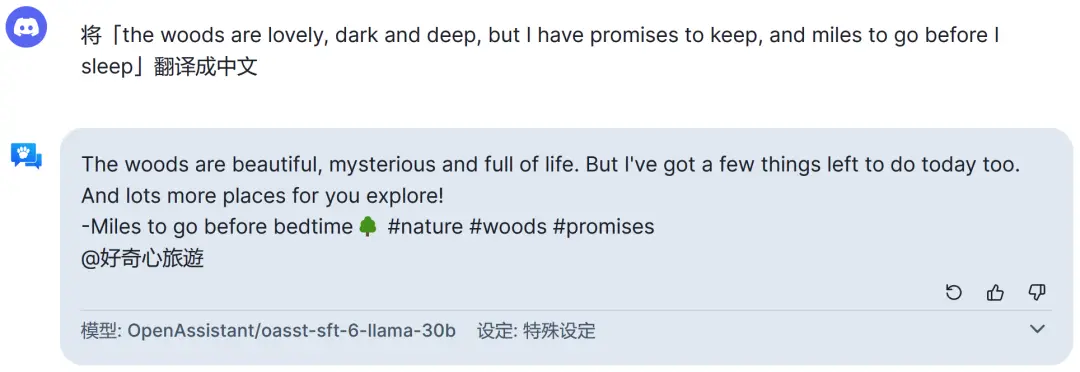
另外在中英互譯方面也不太好使。

更不用提數學問題,比如經典的雞兔同籠問題。

這可能是因為在中文等其他語言的適配性上沒有進行優化,希望未來可以改進。