對某些人來說,人工智能助手就像我們的好朋友,我們可以向他們提出任何敏感或尷尬的問題。畢竟,我們與它們的通信是加密的,這看起來很安全。然而,以色列的研究人員發現黑客規避這種保護的方法。
和其他優秀的助手一樣,人工智能對你如指掌。它知道你住在哪裡,在哪裡工作。它可能知道你喜歡吃什麼食物,這個周末打算做什麼。如果你特別健談,它甚至可能知道你是否在考慮離婚或考慮破產。
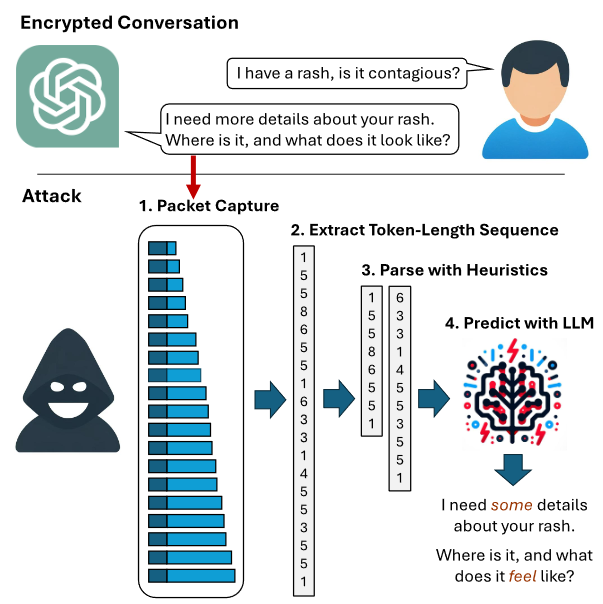
這就是為什麼研究人員設計的一種可以通過網絡讀取人工智能助手加密回復的攻擊令人震驚。這些研究人員來自以色列的進攻型人工智能研究實驗室(Offensive AI Research Lab),他們發現,除Google Gemini之外,大多數使用流媒體與大型語言模型交互的主要人工智能助手都存在一個可利用的側信道。然後,他們演示如何利用 OpenAI 的 ChatGPT-4 和微軟的 Copilot 的加密網絡流量。
研究人員在論文中寫道:"我們能夠準確地重建 29% 的人工智能助手的回答,並成功地從 55% 的回答中推斷出主題。"
最初的攻擊點是標記長度側信道。研究人員解釋說,在自然語言處理中,標記是包含意義的最小文本單位。例如,"我的皮疹很癢"這句話可以標記化如下:S = (k1, k2, k3, k4, k5),其中標記為 k1 = I, k2 = have, k3 = an, k4 = itchy, k5 = rash。
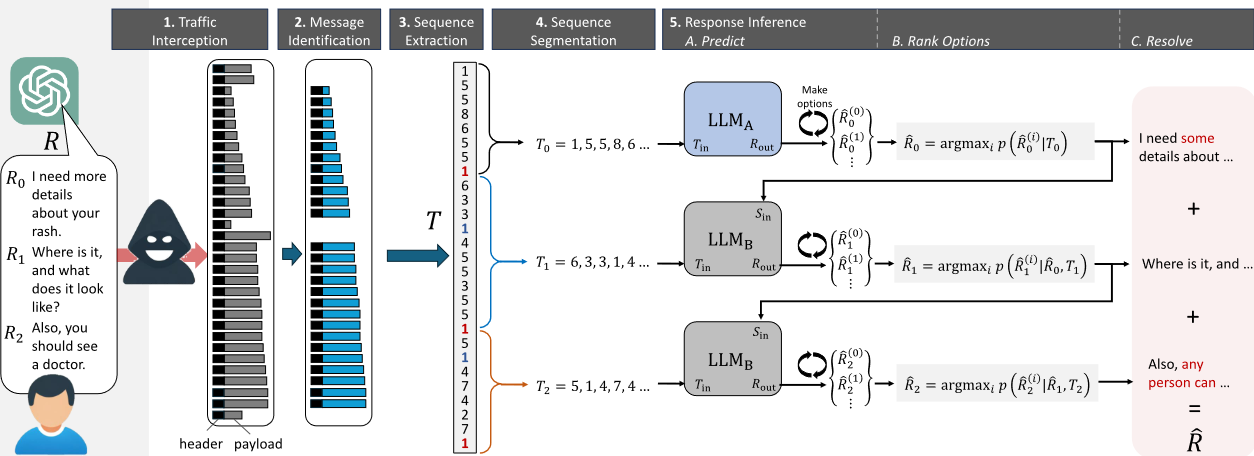
然而,令牌是大型語言模型服務處理數據傳輸的一個重要漏洞。也就是說,當 LLM 以一系列令牌的形式生成和發送響應時,每個令牌都會在生成的同時從服務器發送給用戶。雖然這一過程是加密的,但數據包的大小會泄露令牌的長度,從而有可能讓網絡上的攻擊者讀取對話內容。
研究人員說,從標記長度序列推斷回復內容具有挑戰性,因為回復可能長達數句,從而產生數百萬個語法正確的句子。為解決這個問題,他們:(1)使用大型語言模型來翻譯這些序列;(2)為 LLM 提供句子間上下文,以縮小搜索空間;(3)根據目標模型的寫作風格對模型進行微調,從而進行已知純文本攻擊。
他們寫道:"據我們所知,這是第一項使用生成式人工智能進行側信道攻擊的工作。"
研究人員已經就他們的工作聯系至少一傢安全廠商 Cloudflare。自從接到通知後,Cloudflare 表示它已經實施一項緩解措施,以保護自己名為 Workers AI 的推理產品的安全,並將其添加到 AI Gateway 中,以保護客戶的 LLM,無論它們在哪裡運行。
在論文中,研究人員還提出一項緩解建議:在每條信息中加入隨機填充,以隱藏信息流中標記的實際長度,從而使僅根據網絡數據包大小來推斷信息的嘗試變得更加復雜。