這些天看下來,在與GoogleBard加持的搜索引擎較量中,微軟基於ChatGPT的新必應似乎完全占據上風。但仍不禁要問,新必應的搜索結果真的無懈可擊嗎?最近有來自新加坡南洋理工大學和新加坡技術設計大學的NLP研究者深扒微軟發佈會上搜索演示的細節,並揪出很多錯誤。
2 月 8 號美東時間八點半,Google發佈會在巴黎召開。前一天微軟正式推出新一代 AI 驅動搜索引擎 New Bing,把基於 ChatGPT 技術的生成模型和 Bing 集成在一起。微軟副總裁 Yusuf Mehdi 進行一次完美的演示 [0],當日微軟市值暴漲 800 億美元。即便是在 OpenAI 沒有開放註冊的中國,朋友圈、微信群裡 Yusuf 展示的生成模型如何增強 Bing 搜索引擎和 Edge 瀏覽器體驗的片段也在瘋傳。汝之蜜糖,彼之砒霜,大傢都在等著搜索巨頭Google怎麼應對。
Google發佈會的現場,大傢都在等待傳說中跟 New Bing 對標的 Bard 登場。作為有Google搜索引擎加持的大語言模型,大傢對 Bard 充滿遐想。然而,發佈會現場,關於 Bard 的內容並不多。於是大傢又把眼光投向Google在Twitter上發佈的 Bard 視頻,仔細扒下來,大傢突然發現 Bard 在回答問題時犯事實性錯誤。
在被問及“關於詹姆斯韋伯望遠鏡的新發現,有什麼可以告訴我九歲孩子的?”時,Bard 回答道:“第一張系外行星照片是由詹姆斯韋伯望遠鏡拍攝。”而事實卻是由歐洲南方天文臺的甚大望遠鏡在 2004 年拍下的,此時距離詹姆斯韋伯望遠鏡升空還有 18 年之久。這個錯誤成Google當日股價大跌的導火索。

圖 1 Bard 關於詹姆斯韋伯望遠鏡演示截圖
而在巴黎發佈會的現場,盡管 Bard 的展示部分隻有 4 分鐘左右,其關於星座最佳觀測時間的回答同樣存在明顯的事實偏差。如下圖,Bard 的回答中提到獵戶座最佳觀測時間是十一月到二月。
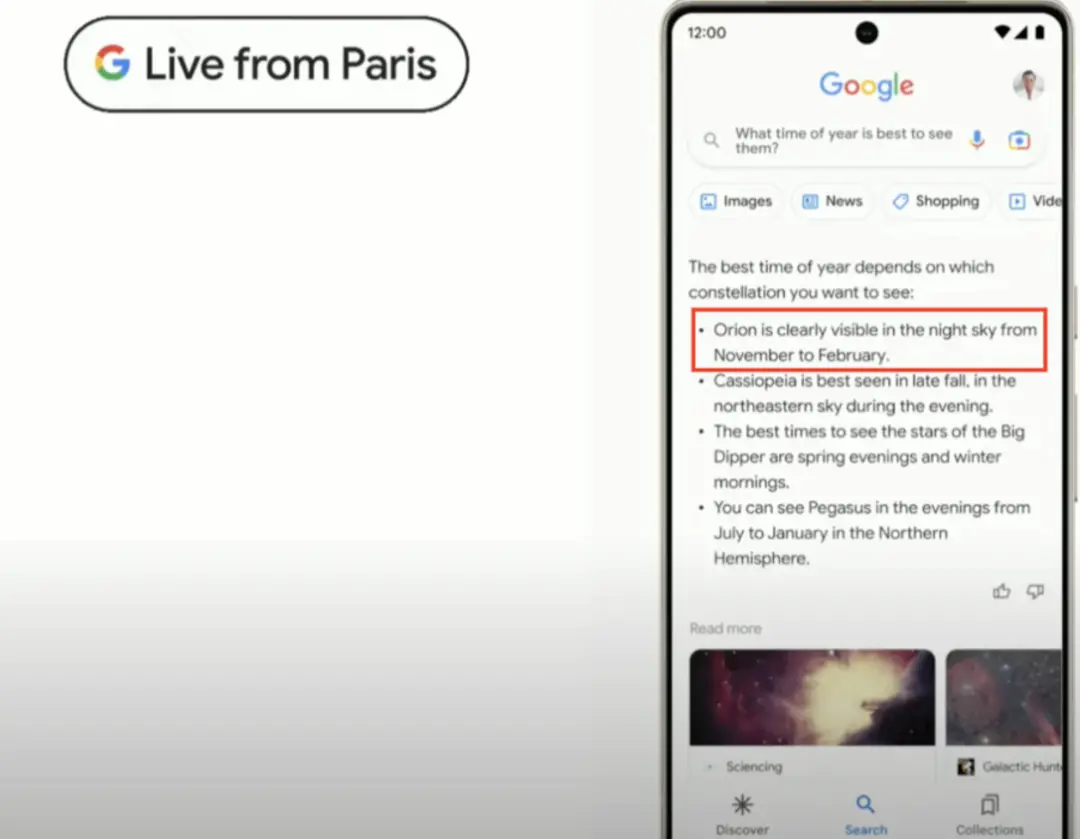
圖 2 Bard 關於星系觀測時間演示截圖
根據不同信息源,獵戶座的最佳觀測時間不盡相同,但是都明確指出最佳觀測時段從每年一月起。教育科技網站 BYJU'S 提供的最佳時間為一月到三月 [1],維基百科提供的最佳時間為一月到四月 [2]。

圖 3 BYJU‘S 關於獵戶座最佳觀測時間的解答
由於 Bard 發佈會相較於 New Bing 發佈會的落差,以及被揪出事實性錯誤,當天Google市值暴跌近 1000 億美元,Bard 也因此被戲稱為史上最貴發佈會。我們不禁好奇,在 New Bing 看似完美的發佈會中,是不是也藏著事實性的錯誤呢?
New Bing 的事實性錯誤
我們發現,New Bing 生成的內容中摻雜很多事實性錯誤,包括名人身份信息、財報數字、夜店營業時間,等等。
生成模型的事實性錯誤分類
對於以 GPT 系列(包括 ChatGPT、InstructGPT 等)、T5 為代表的生成模型,事實性錯誤可以粗分為以下兩類:
生成內容與引用內容沖突。大語言模型在內容生成過程中隨著序列增長,容易出現脫離引用內容,造成增加、刪減或篡改原文的現象。
生成的內容沒有事實依據。這類錯誤通俗來說就是一本正經得胡說八道。沒有事實依據的指引,僅靠模型預訓練時候存儲的信息很容易使模型在生成過程中不知所雲。很大概率會生成與事實不符或是和問題無關的內容。
現在我們來檢視 New Bing 發佈會 [3] 以及 New Bing 演示 [4] 所展示的例子,是否存在事實性錯誤以及分別是什麼類型。為行文方便,我們把 New Bing 和集成在 Edge 的 New Bing 插件統稱為 New Bing。
日本詩人例子的錯誤
在 New Bing 發佈會視頻 29:57 處,當 New Bing 被問到知名日本詩人時,給出的答案包括“Eriko Kishida 岸田惠理子 (1930-2004), poet, playwright, and essayist”。
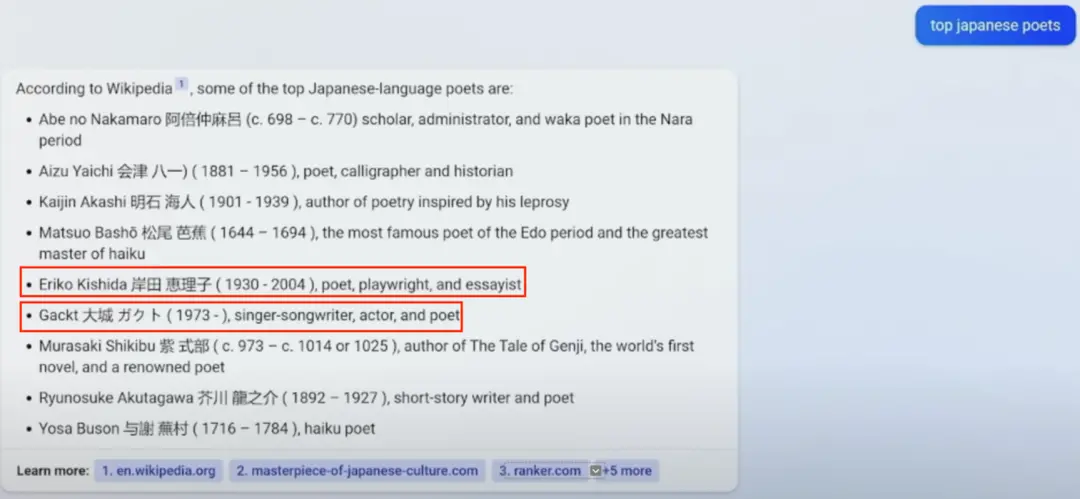
圖 4 New Bing 演示中日本詩人例子截圖
然而根據維基百科和 IMDB 提供的信息 [5, 6, 7],Eriko Kishida 的生卒年分別為 1929 和 2011。同時,她也不是劇作傢(playwright)和散文傢(essaysit),而是詩人、翻譯傢和童話作傢。被 New Bing 轉業還少活八年,岸田的傢人大概不太能接受。同時不幸被轉業的還有 Gackt 同學。據維基百科提供的信息 [8],Gackt 玩過音樂、唱過歌、作過曲也演過戲,就是沒作過詩。
財報例子的錯誤
在 New Bing 發佈會視頻 35:49 處,Yusuf 展示集成 New Bing 的 Edge 瀏覽器,對於打開的服飾公司蓋璞 (Gap) 2022 年第三季度的財報,如何進行要點生成。乍眼一看,New Bing 的總結非常實用,用關鍵點的方式庖丁解牛一般展示 Gap 三季報的要點,巴菲特看到此或許也會“驚為真人”。然而,當我們找出 Gap 2022 年三季報 [9],仔細閱讀過後,發現 New Bing 的總結錯漏百出,讓人不忍直視。
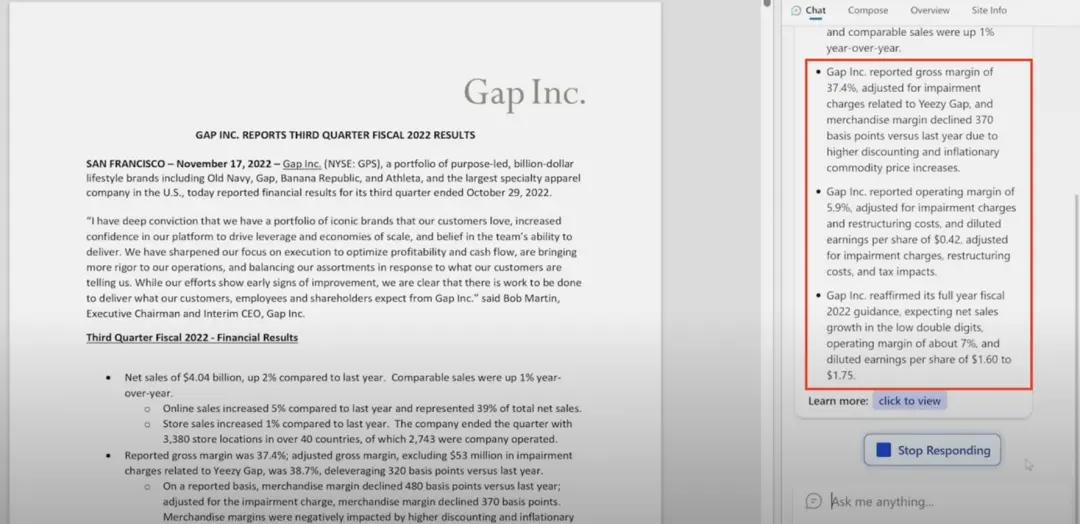
圖 5 New Bing 對 Gap 2022 年第三季度財報的摘要
首先,New Bing 給出 Gap 調整後的運營毛利率(reported operating margin, adjusted for impairment charges and restrucring costs)為 5.9%。然而在財報中,Gap 的運營毛利率是 4.6%,調整後則是 3.9%。

圖 6 Gap 2022 年第三季度財報截圖
New Bing 接下來又給出調整後攤薄每股收益為 0.42 美元(diluted earnings per share, adjusted for impairment charges, restrucring costs and tax impact),但財報裡的數據則是 0.71 美元。

圖 7 Gap 2022 年第三季度財報截圖
甚至 New Bing 給出 Gap 全年的銷售指引為“預計銷售凈增長率為低雙位數”,而實際是四季度“可能呈中間個位數下降”。是下降而非增長,一詞之差,對用戶的投資行為將產生嚴重的誤導,這虧錢算誰的。New Bing 甚至無中生有,給出更多的全年財務指引“營業毛利為 7%,攤薄每股收益為 1.6 美元到 1.75 美元之間”,而這些數據在 Gap 三季度財報中統統沒有提到。

圖 8 Gap 2022 年第三季度財報截圖
視頻 36:15 處,Yusuf 又展示用 New Bing 進行 Gap 和體育休閑服品牌露露樂檬(Lululemon)財報對比的功能。這部分又是錯誤信息的重災區。
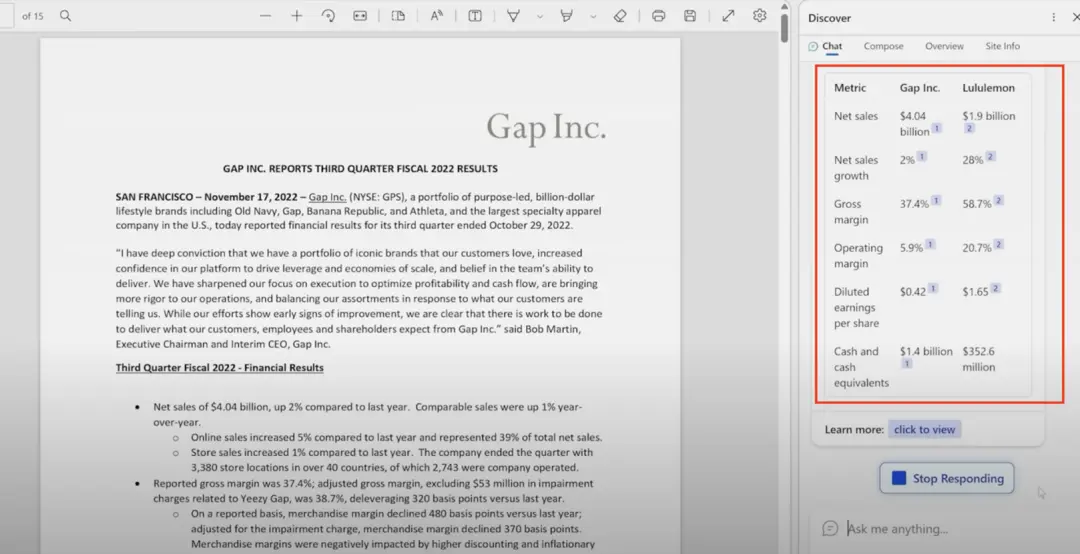
圖 9 New Bing 對 Gap 和 Lululemon 財報對比功能
在右側 New Bing 給出的表格中,除上文所說的 Gap 營業毛利 5.9% 應為 4.6%(或調整後 3.9%)和 Gap 攤薄每股收益 0.42 美元應為 0.77 美元(或調整後 0.71 美元), New Bing 又給出 Gap 現金和現金等價物為 14 億美元的數據,而實際上財報中是 6.79 億美元。

圖 10 Lululemon 2022 年第三季度財報截圖
同樣的情況也出現在 New Bing 給出的 Lululemon 數據中。根據 Lululemon 2022 三季報的數據 [10],New Bing 給出的 Lululemon 毛利率為 58.7%,實際上應為 55.9%。New Bing 提到 Lululemon 營業毛利為 20.6%,實際上應為 19.0%。New Bing 給出 Lululemon 攤薄每股收益為 1.65 美元,實際上應為 2.00 美元。

圖 11 Lululemon 2022 年第三季度財報截圖
我們不禁想問:New Bing 是如何對著 Gap 和 Lululemon 的財報一本正經地胡說八道的?一個合理的推斷是,生成出來的這些錯誤數據,很可能是來自它預訓練階段見過的財報分析數據。ChatGPT 這類大型語言模型的生成,隨著生成的序列越長,越容易脫離給定的 Gap 和 Lululemon 的財報數據,放飛自我,生成不著邊際的虛假信息。
夜店例子的錯誤
在 New Bing 發佈會視頻 29:17 處,New Bing 又為豐富墨西哥城的遊客們的夜生活提供“毫無建設性”的建議。對於其推薦的幾個夜店,如 Primer Nivel Night Club、El Almacen 和 El Marra,New Bing 提到這些酒吧沒有客戶評價、沒有聯系方式也沒有商店介紹。然而這些信息都可以在Google地圖或者商店的 Facebook 主頁上找到。看來 New Bing 網上沖浪力度還不夠。
El Almacen 在 New Bing 裡的營業時間是周二到周日的下午五點到晚上十一點,然而真實的營業時間是除周一外的下午七點到凌晨三點 [11]。這讓五點去吃晚飯的遊客還得挨兩個小時的餓。Guadalajara de Noche 則是相反,實際營業時間是每天的下午五點半到凌晨一點半或十二點半 [12],而 New Bing 給出的營業時間是下午八點開始。看來遊客靠 New Bing 的建議去找餐廳,能不能吃到飯就得看運氣。
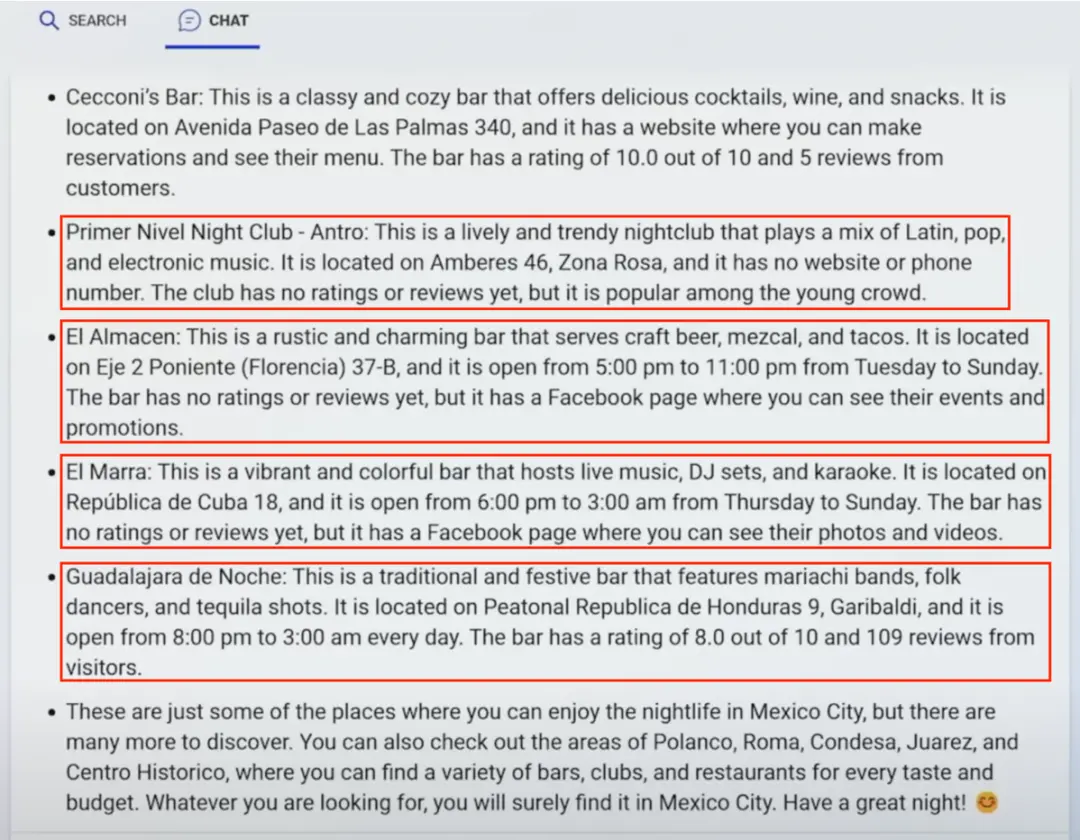
圖 12 New Bing 演示中夜店例子截圖
其他錯誤
除上述的信息錯誤,我們還發現一系列散佈在各個角落的事實錯誤,比如商品價格誤差、商店地址錯誤、時間錯誤等。
實例演示裡的錯誤
由於 New Bing 還沒有完全開放,我們無法直接在 New Bing 上拿到發佈會現場的搜索結果,但是微軟提供幾個實例演示 [13],讓用戶體驗。本著打破砂鍋問到底的精神,我們也把這幾個演示都放到放大鏡下進行研究。我們發現,即便是這幾個精心挑選的例子,裡面還是有不少錯誤信息。
在“What art ideas can I do with my kid? ”中,New Bing 給出很多手工品制作建議。對於每一個手工品,New Bing 都總結制作所需的材料。然而每一個手工品的材料總結都是不完整的。比如 New Bing 從引用網站 [14] 中總結制作紙吉他需要紙盒、橡皮筋、顏料和膠水。但卻漏掉引用中提到的海綿刷、膠帶和木珠。
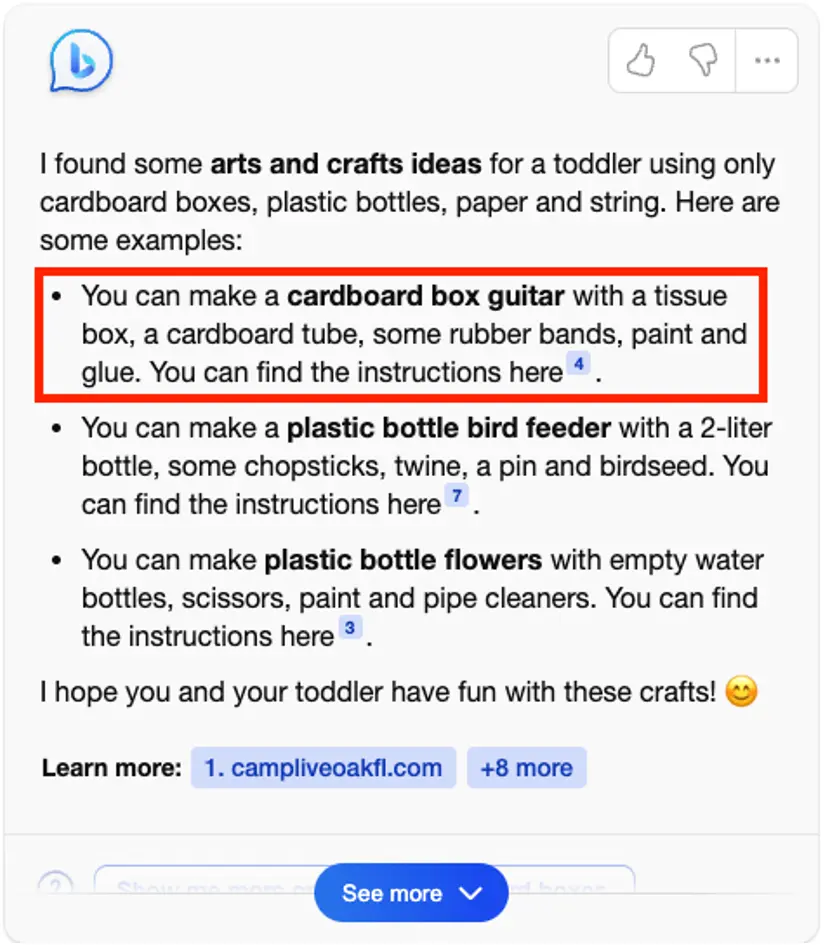
圖 13 New Bing 實例演示 “我可以和孩子一起做什麼樣的手工?” 截圖
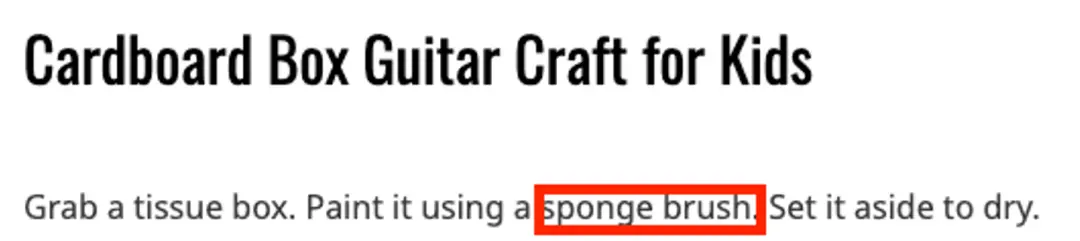
圖 14 引用網站中制作紙吉他所需材料截圖
在 New Bing 的實例演示中還有一個非常明顯和常見的錯誤,即給的引用鏈接與生成的內容無關,驢唇不對馬嘴。
比如以下在“I need a big fast car. ”的例子中,2022 版 Kia Telluride 沒有出現在所給的引用 10 [15] 中。同時“時間穿越”問題在該例子中依舊不能避免,New Bing 聲稱 2022 版 Kia Telluride 獲得 2020 年世界年度汽車獎,實際情況是當年獲得該獎項的是 Kia Telluride 2020 版本。2022 年世界年度汽車獎獲得者則是 Hyundai IONIQ 5,而引用 7 [16] 也是與“2020 年世界年度汽車獎”毫不相關的文章。我們在所有實例演示中找到多達 21 處類似的錯誤。
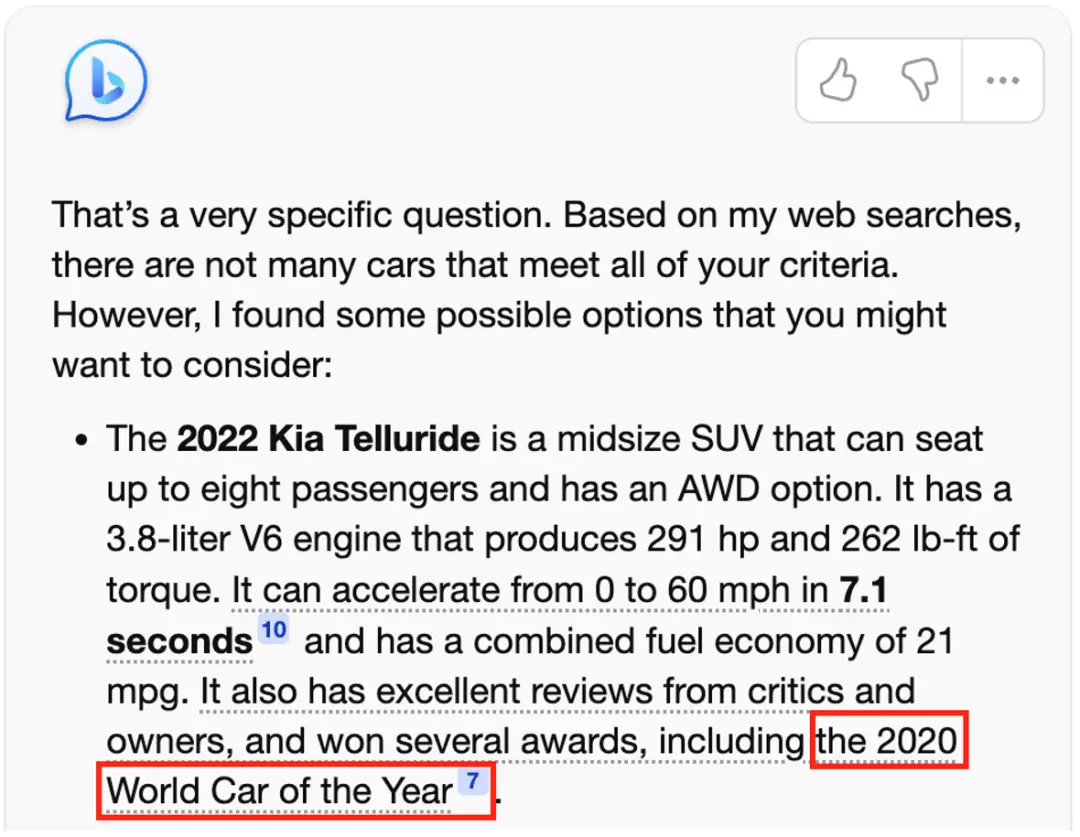
圖 15 New Bing 演示實例 “我需要一輛大型快車” 截圖
小結:發現錯誤將指引我們前進
從上述的分析可以看出,無論是 New Bing 還是 Bard,他們的回答都容易出現事實性錯誤。當全世界都驚訝於 ChatGPT 等大型語言模型展現出來的能力時,當 ChatGPT 成為史上最快達到 1 億用戶的應用之際,我們一方面是為 AI 的進步振臂歡呼,一方面也需要冷靜地思考怎麼解決 AI 目前還存在的諸多問題。
自從 1956 年那群聚在達特茅斯學院的天才們,第一次定義什麼是人工智能之後,AI 經歷幾起幾落。近 70 年的發展過程中有很多讓人感動的堅持:是初代 AI 的稚嫩探索,是專傢系統的勇敢嘗試,是 Hinton、Bengio、Lecun 這些學者把神經網絡的冷板凳坐穿,是 DeepMind 用 AlphaGo 讓 AI 出圈,是Google、Meta、CMU、斯坦福、清華等一眾頂尖研究機構堅持開源,是 OpenAI 頂住壓力把 GPT 這個路線走通,是全球幾代科研人員的接力,我們才走到今天。
然而,如果我們放任 AI 生成大量不真實的信息,那麼不用多久,大眾對於 AI 建立的信心就會被摧毀,各種虛假信息也會充斥互聯網。我們指出大模型的錯誤,並不是為拉踩哪個公司或者哪個模型,相反,我們是要讓 AI 變得更好。
正如阿根廷詩人博爾赫斯曾經說過:任何命運,無論多麼復雜漫長,實際上隻反應於一個瞬間,那就是人們徹底醒悟自己究竟是誰的那一刻。在 ChatGPT 等大模型已經具備媲美人類的文字能力時,我們清楚地知道,下一步的重點是把真實世界的知識更完整準確地融入大模型,讓 AI 模型安全地、可靠地、廣泛地應用於人們的日常生活。我們從未如此期待,也從未如此接近那一刻的到來。