當微軟和Google為誰的人工智能聊天機器人更好而使出渾身解數時,我們不難發現這並不是機器學習和語言模型的唯一用途。除傳聞中計劃在今年的年度GoogleI/O活動中展示20多種由人工智能驅動的產品外,Google正在朝著建立一個支持1000種不同語言的人工智能語言模型的目標邁進。
在周一發佈的更新中,Google分享有關通用語音模型(USM)的更多信息,Google稱這一系統是實現其目標的"關鍵第一步"。
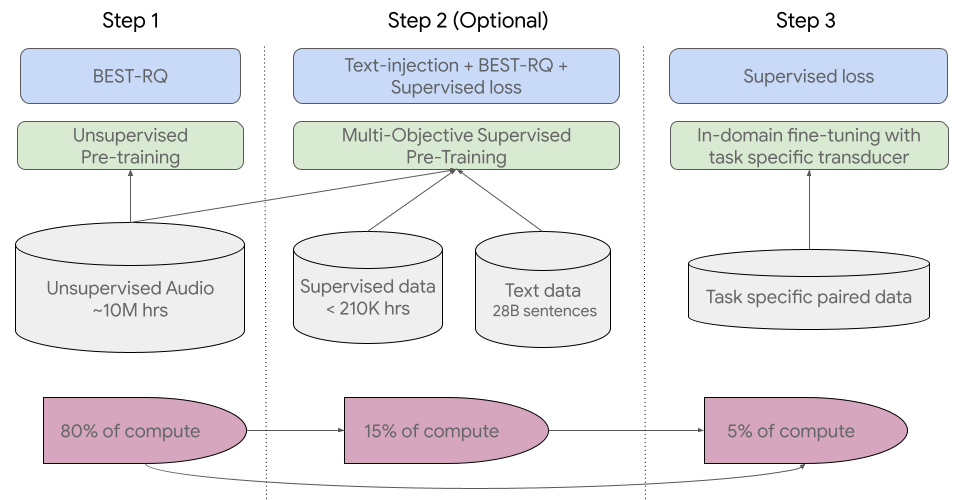
去年11月,該公司宣佈其計劃創建一個支持全球1000種最常用語言的語言模型,同時還披露其USM模型。Google將USM描述為"一個最先進的語音模型系列",它有20億個參數,在1200萬小時的語音和超過300種語言的280億個句子中進行訓練。
YouTube已經使用USM來生成封閉式字幕,它還支持自動語音識別(ASR),這可以自動檢測和翻譯語言,包括英語、中文普通話、阿姆哈拉語、宿務語、阿薩姆語等等。
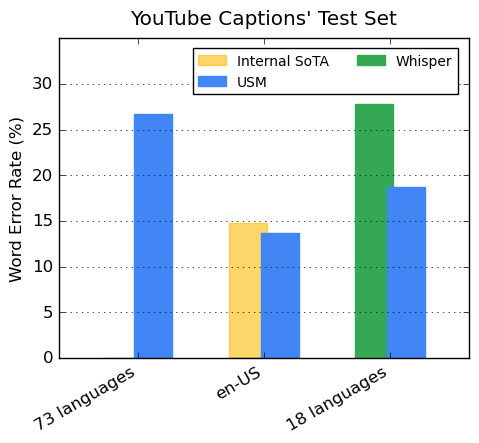
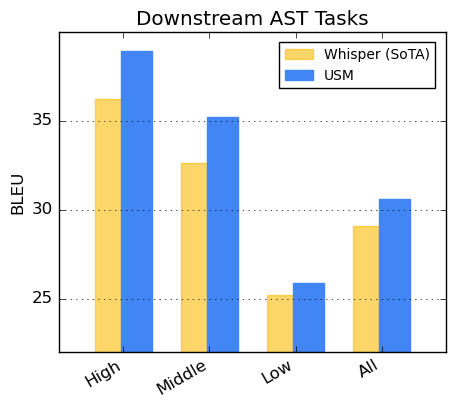
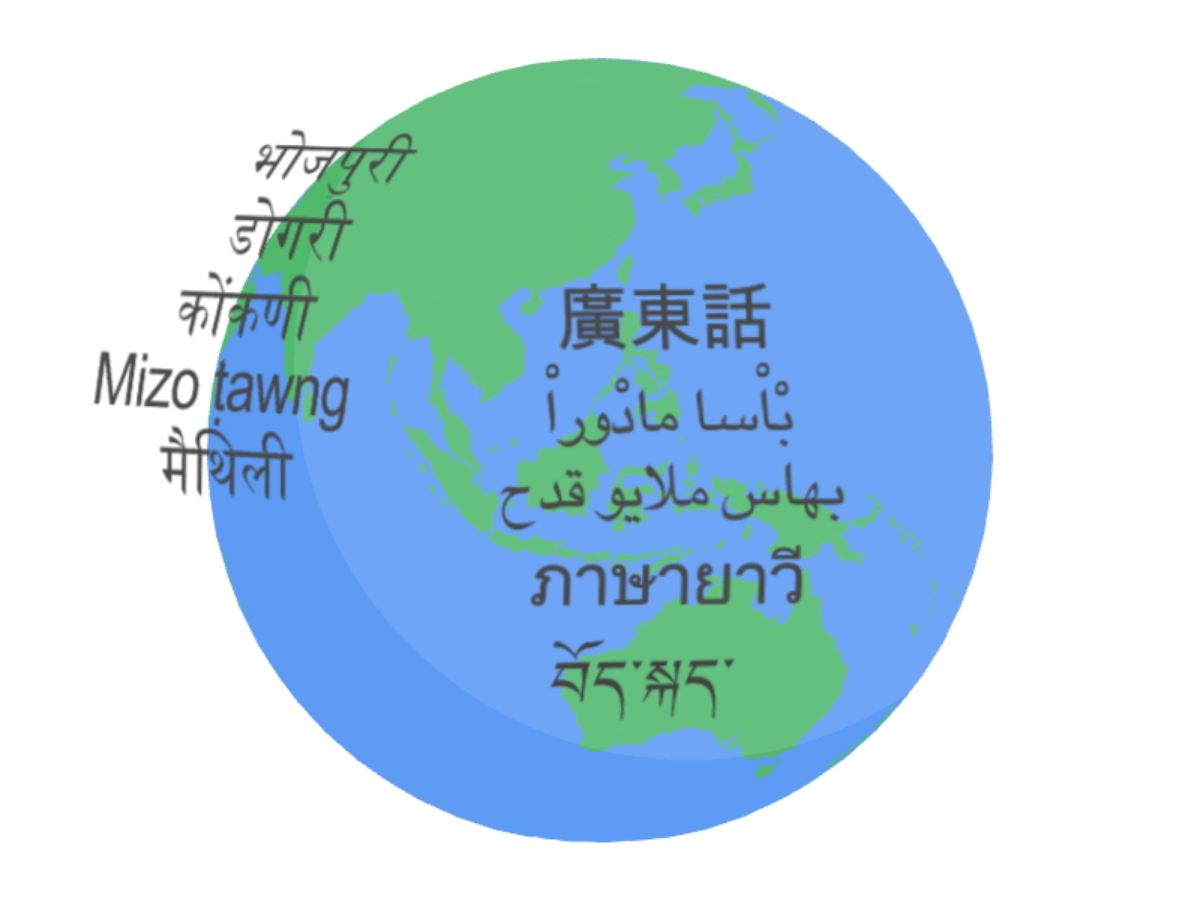
現在,Google USM支持超過100種語言,並將作為"基礎"來建立一個更加廣泛的系統。與此同時,Meta公司正在開發一個類似的人工智能翻譯工具,但目前仍處於早期階段。
您可以在Google發佈的研究論文中閱讀更多關於USM和它如何工作的信息:
https://arxiv.org/abs/2303.01037
該技術的一個目標可能是在增強現實的眼鏡內,就像Google去年在I/O活動中展示的概念一樣,能夠檢測並提供實時翻譯,不過,這項技術似乎還有點遙遠,Google在I/O大會期間對阿拉伯語的錯誤表述證明它是多麼容易出錯。