人工智能聊天機器人最受人詬病的行為之一就是所謂的幻覺,即人工智能在令人信服地回答問題的同時,卻向你提供與事實不符的信息。簡單地說,就是人工智能為滿足用戶的需求而胡編亂造。
在使用生成式人工智能創建圖片或視頻的工具中,這就不是一個問題。最後,最近才從 OpenAI 離職的知名專傢安德烈-卡爾帕西(Andrej Karpathy)竟然說,產生幻覺的現象是生成式人工智能的底層技術--大型語言模型(LLM)的最大特點。
但是,在以文本為重點、基於 LLM 的聊天機器人中,用戶希望所提供的信息與事實相符,因此幻覺是絕對不允許出現的。
防止人工智能產生幻覺是一項技術挑戰,而且並非易事。不過,據Marktechpost報道,Google DeepMind 和斯坦福大學似乎找到某種變通辦法。
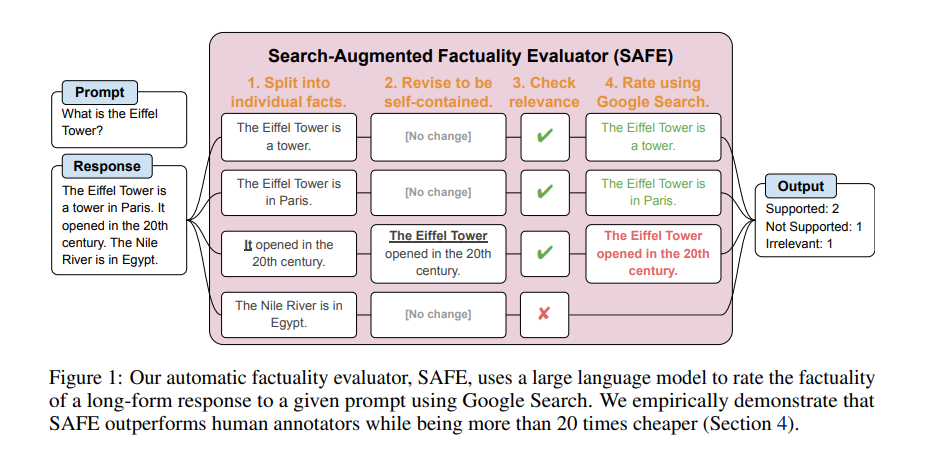
研究人員提出一種基於 LLM 的系統--"搜索增強事實性評估器"(Search-Augmented Factuality Evaluator,簡稱 SAFE),它可以對人工智能聊天機器人生成的長格式回復進行事實檢查。他們的研究成果連同所有實驗代碼和數據集已作為預印本發表在 arXiv 上。
系統通過四個步驟對答案進行分析、處理和評估,以驗證其準確性和真實性。首先,SAFE 將答案分割成單個事實,對其進行修改,並與Google搜索結果進行比較。系統還會檢查各個事實與原始問題的相關性。
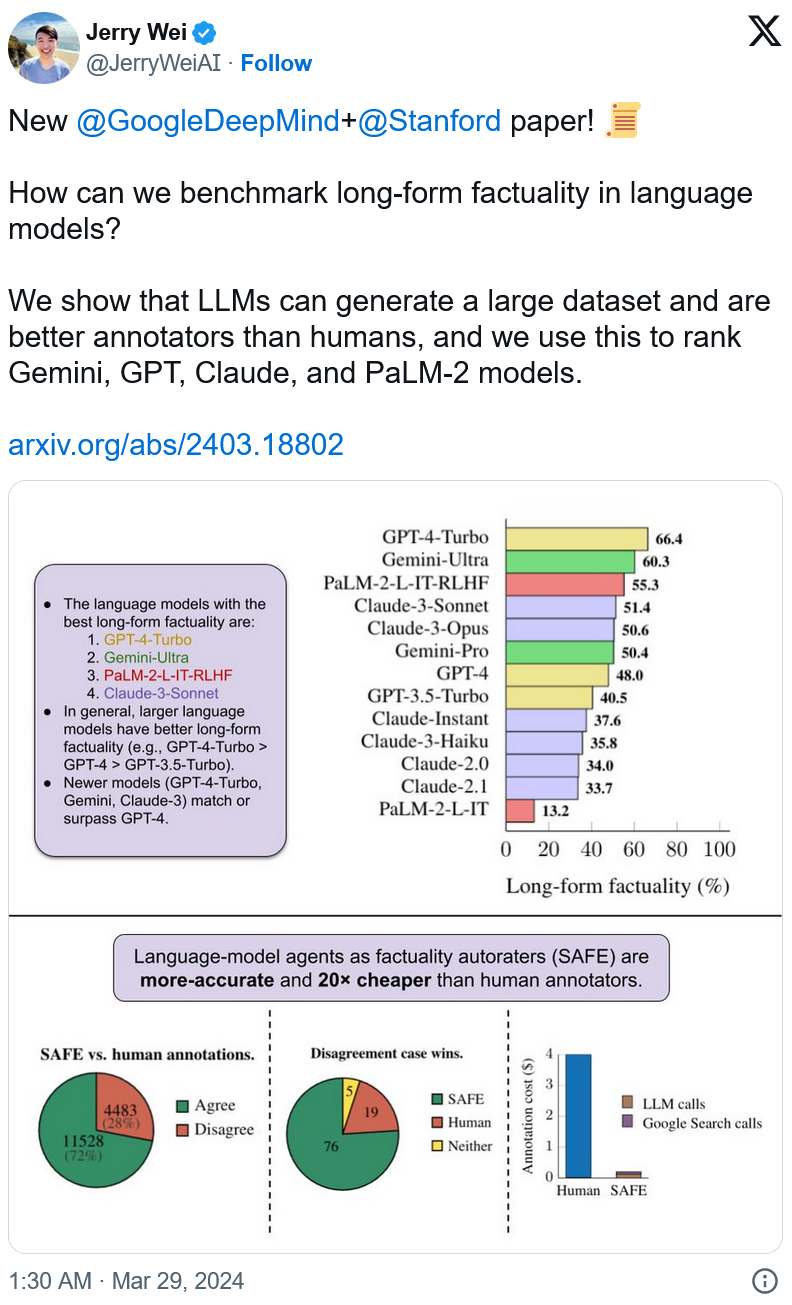
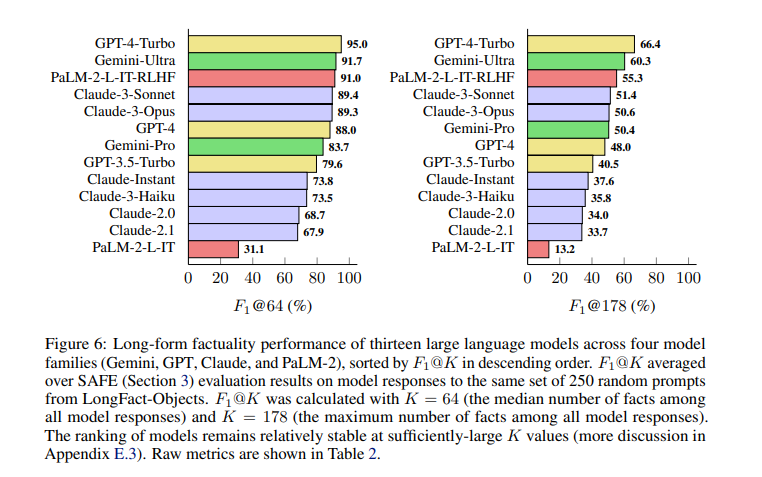
為評估 SAFE 的性能,研究人員創建一個包含約 16,000 個事實的數據集 LongFact。然後,他們在四個不同系列(Claude、Gemini、GPT、PaLM-2)的 13 個 LLM 中測試該系統。在 72% 的情況下,SAFE 提供與人類註釋者相同的結果。在存在分歧的情況下,SAFE 的正確率為 76%。
此外,研究人員還聲稱,使用 SAFE 的成本比人工註釋員或事實檢查員低 20 倍,因此提供一個經濟可行的解決方案,而且可以大規模應用。